Differences between ARM Cortex-A8 and Cortex-A9 arm cortex a9刷机包
Differences between ARM Cortex-A8 and Cortex-A9 (eg: iPad 1 vs iPad 2):
Cortex-A9 has many advanced features for a RISC CPU, such as speculative data accesses, branch prediction, multi-issuing of instructions, hardware cache coherency, out-of-order execution and register renaming. Cortex-A8 does not have these, except for dual-issuing instructions and branch prediction. Therefore Assembly code optimizations &NEON SIMD are not as important in Cortex-A9 anymore.
Cortex-A9 has 32 bytes per L1 cache line, whereas Cortex-A8 has 64 bytes per cache line.
Cortex-A9 has an external L2 cache (a separate "outer" PL310 or new L2C-310 chip), whereas Cortex-A8 has an internal L2 cache (on-chip "inner" cache, therefore faster).
Cortex-A9 MPCore has separate L1 Data and Instruction caches for each core, with hardware cache coherency for the L1 Data cache but not the L1 Instruction cache. Any L2 cache is shared externally between all the cores.
Cortex-A9 must use the PreLoad Engine in the external L2 cache controller (if it has one), whereas Cortex-A8 has an internal PLE for its L2 cache.
Cortex-A9 has a full VFPv3 FPU, whereas Cortex-A8 only has VFPLite. The main difference being that most float operations take 1 cycle on Cortex-A9 but take 10 cycles on Cortex-A8! Therefore VFP is very slow on Cortex-A8 but decent on Cortex-A9.
Cortex-A9 allows half-precision (16-bit) floats, whereas Cortex-A8 only allows 32-bit singles and 64-bit floats. But half-precision has almost no supported operations directly anyway.
Cortex-A9 can't dual-issue multiple NEON instructions, whereas Cortex-A8 can potentially dual-issue certain NEON load/store instructions with other NEON instructions.
Cortex-A8 had the NEON unit behind the ARM unit, so NEON had fast access to ARM registers & memory but it took 20 cycles delay for any registers or flags from NEON to reach the ARM! This often occurs with function return values (unless if "hardfp" convention or function inlining is used).
Cortex-A8 had a separate load/store unit for NEON and one for ARM, so if they were both loading or storing addresses in the same cache line, it adds about 20 cycles delay.
Cortex-A9 uses LDREX/STREX for multi-threaded synchronization without blocking all cores, whereas Cortex-A8 uses simple disabling of interrupts for mutexes.
All Cortex-A8 CPUs have a NEON SIMD unit, where some Cortex-A9 CPUs don't have a NEON SIMD unit (eg: nVidia Tegra 2 does not have NEON, but nVidia Tegra 3 will have NEON).
Notes on ARM Cortex-A9 or any ARM Cortex-A in general:
Cortex-A9 has a 4-way set associative L1 Data Cache using 32 bytes per cache line (16kB, 32kB or 64kB of L1 cache, which is 512, 1024 or 2048 L1 cache lines).
Cortex-A9 MPCore can't clean or invalidate both L1 & external L2 at the same time, so incoherency can occur unless if done in correct order by softare: To clean, clean the L1 cache first then L2, or to invalidate, invalidate the L2 cache first then L1.
Cortex-A9 contains a "Fast Loop Mode" where very small loops (under 64 bytes of code and possibly cache line aligned) can run completely in the CPU decode & prefetch stages without accessing the instruction cache.
Cortex-A9 has support for Automatic Data Prefetching (if enabled by the OS), so that if you are accessing 1 or 2 arrays sequentially, it will detect this and prefetch the next data to cache before you will need it.
Cortex-A9 can detect when the instruction STM is used for memset() & memcpy(), and optimize the cache access by not loading data into cache if it will be overwritten anyway.
Cortex-A9 MPCore has a separate NEON module for each core. eg: a quad-core Cortex-A9 has 4 NEON units!
If the TLB does not have an page in its table, then a "page table walk" needs 2 or 3 memory accesses instead of 1.
"char" variables on ARM may default to unsigned chars, whereas they default to signed chars on x86, so this can cause runtime errors if not expected.
The first 4 arguments to a function are sent directly in the first 4 32-bit registers, whereas the rest of arguments use stack memory so are slower. But C++ automatically uses the 1st argument as a pointer to "this", so only 3 function arguments can go in registers.
64-bit arguments are more tricky and limiting due to the 8-byte alignment requirement.
If a function will call another function, it needs to maintain an 8-byte stack alignment, so should PUSH/POP an even number of times. Leaf functions don't need 8-byte stack alignment.
When passing arguments with NEON Advanced SIMD using the "hardfp" calling convention, registers q0-q3 (s0-s15 or d0-d7) are used. Registers q4-q7 (s16-s31 or d8-d15) must be preserved if modified.
Newer C99 compilers allow the "restrict" keyword to say that pointers do not overlap other pointers, allowing compiler optimizations.
Cortex-A does not have integer division, so any divide instruction is a slow (~50 cycle) function call or floating-point divide. But shifts left or right are often free.
Since the Branch Target Address Cache (BTAC) is based on 16-byte sizes and only allows 2 branches per line, if any code has more than 2 branches within 16-bytes of code, then it is likely to flush the instruction pipeline.
Since Cortex-A9 does Register Renaming at upto 2 registers per cycle, LDM or STM instructions of 5 or more registers can cause pipeline stalls.
Conditional Execution of ARM mode (not Thumb) allowed speedups in older CPUs but now it is often faster to use branches, because conditional instructions may need unwinding.
Good info on optimizing memset() & memcpy() is given on page 17.19 of the ARM Programmers Guide, saying to use LDM & STM of a whole cache line, where aligned store is more important than aligned load, and upto 4 PLD's should be inserted, for roughly 3 cache lines ahead of current cache line.
Some info on optimizing float operations with VFP are given in Chapter 18 of the ARM Programmers Guide.
The Cortex-A9 has a big delay when switching between VFP and NEON instructions.
NEON can't process 64-bit floats, divisions or square roots, so they are done with VFP instead.
NEON can be detected at compile time by checking: #ifdef __ARM_NEON__
NEON can be detected at runtime on Linux by checking the CPU flags, by running "cat /proc/cpuinfo" or searching the file "/proc/self/auxv" for AT_HWCAP to check for the HWCAP_NEON bit (4096).
Cortex-A9 MPCore uses the MESI protocol to keep all L1 caches coherent. Unfortunately, if a thread is often writing to a piece of data and another thread is often reading from a different piece of data on the same cache line, that cache line is transferred significantly (thrashed).
The ARM DS-5 development suite generates faster code than GCC/LVDS compilers and has a more powerful debugger (using Eclipse IDE) that can analyze the system non-intrusively using CoreSight or JTAG.
The ARM "Vector Floating Point" (VFP) module was intended for SIMD vector operations, but it never became so! The VFP unit is just a scalar FPU for 32-bit floats and 64-bit doubles.
The ARM "Advanced SIMD" (NEON Media Processing Engine) unit is a true SIMD unit for integers (8, 16, 32 or 64 bit signed or unsigned), floats (32-bit only, plus limited 16-bit half-precision float support) and 16-bit binary polynomials.
更多阅读
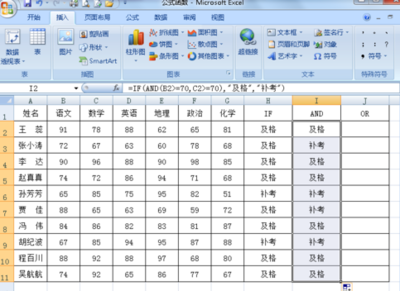
如何使用 IF AND OR 条件函数 if or函数
如何使用 IF AND OR 条件函数——简介在工作和日常生活中都会用到Excel表格中的公式和函数,在数据筛选的时候尤为重要,下面让咱们一起认识下IF、AND和OR函数的用法IF函数是判断式的计算函数,假设单元格的值检验为True(真)时,就执行条件成
三星N7100刷机教程 三星手机怎么刷机
三星N7100刷机教程——简介三星Galaxy Note II 采用5.5英寸Super AMOLED屏幕,屏幕分辨率为WXGA(1280*720)。除屏幕外。这款设备还搭载自家Exynos 5250 ARM-15四核处理器,内置2GB RAM,支持4G网络连接。前置190万和后置800像素的摄像头。

英文谚语.完全版 英文谚语精选
英文谚语.完全版Safe and sound 安然无恙Safe bind, safe find. 藏的稳,找的准A saint abroad and a devil at home. 在外是圣人,在家是魔鬼salt of the earth 社会中坚The same knife cuts bread and fingers. 同是一把刀,切面包时也

Great Changes in Chinese Family Life changes in my life
Candy 3006205313Great changes have taken place in Chinese family life in the past 60 years. There have been great differences between our grandparents’ life and ours, not only in terms of house, but also in terms

智能手机热点趋势 智能手机趋势
国际电子商情讯 市场调查公司Ovum表示,智能手机制造商陆续采用含有先进的图形与影音处理能力的高效能硬件,逐渐从ARM-11系列处理器过度到ARM Cortex A8,且Qualcomm(高通)Snapdragon芯片也正在紧锣密鼓的筹备中。然而,Nokia似乎在这场大