发布时间:2018年04月10日 22:58:48分享人:讨喜冤家来源:互联网21
上期回顾:上篇说明了分解非季节性数据的方法。就是通过TTS包的SMA()函数进行简单移动平均平滑。让看似没有规律或没有趋势的曲线变的有规律或趋势。然后再进行时间序列曲线的回归预测。
本次,开始分解季节性时间序列。
一个季节性时间序列中会包含三部分,趋势部分、季节性部分和无规则部分。分解时间序列就是要把时间序列分解成这三部分,然后进行估计。
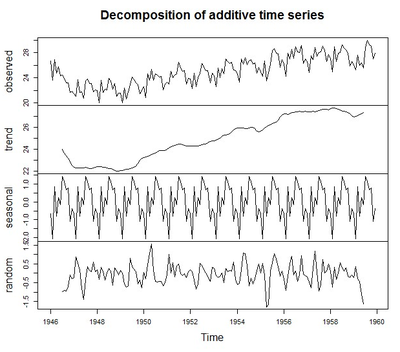
对于可以使用相加模型进行描述的时间序列中的趋势部分和季节性部分,我们可以使用R中的“decompose()” 函数来估计。这个函数可以估计出时间序列中趋势的、季节性的和不规则的部分,而此时间序列须是可以用相加模型描述的。“decompose()” 这个函数返回的结果是一个列表对象, 里面包含了估计出的季节性部分,趋势部分和不规则部分,他们分别对应的列表对象元素名为“seasonal” 、 “trend” 、 和“random”。
示例:纽约每月出生人口数量是在夏季有峰值、 冬季有低谷的时间序列。
> births<-scan("http://robjhyndman.com/tsdldata/data/nybirths.dat")Read 168 items> birthstimeseries <- ts(births,frequency=12, start=c(1946,1))> ts.plot(birthstimeseries)
> birthcomponents <-decompose(birthstimeseries)> plot(birthcomponents)而当你需要剔除某个趋势时(我们就去掉季节因素),我们可以运用减法去掉该因素,下图就是去掉季节性因素后的修正序列。>birthstimeseriesseasonallyadjusted<-birthstimeseries-birthcomponents$seasonal>plot(birthstimeseriesseasonallyadjusted)留下记录,供日后复习应用。
爱华网本文地址 » http://www.aihuau.com/a/25101013/187564.html
更多阅读
黑马程序员-网络编程基础---------------------------android培训、java培训、期待与您交流!--------
任务:按自由度为6的卡方分布进行随机抽样(样本量为200),绘出样本的柱状图,经验分布图,P-P图和Q-Q图。效果如下:code如下:set.seed(10086)n <- 200df <
Boost.Tokenizer用容器的表现形式将一个字符串或其它字符序列分解为一系列单词(Token)所需头文件:分解例子typedefboost::tokenizer<boost::char_separator<char>> Token;boost::char_separator<char> sep(",;");std::string str(
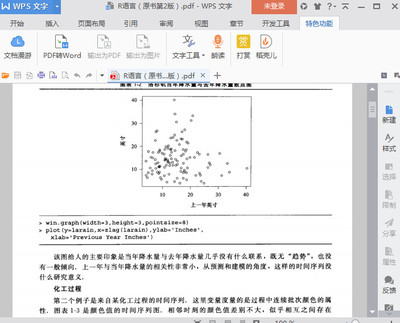
时间序列分析一、时间序列数据1.数据类型:截面数据与时间序列数据人们对统计数据往往可以根据其特点从两个方面来切入,以简化分析过程。一个是研究所谓横截面(crosssection)数据,也就是对大体上同时,或者和时间无关的不同对象的观测值组
美国非农就业数据是美国失业率数据中的一项,反应出农业就业人口以外的新增就业人数,和失业率同时发布,由美国劳工部统计局在月第一个星期五美国东部时间8:30也就是北京时间晚上20:30前一个月的数据 。目前为止,该数据是美国经济指标中