一、爬行与抓取
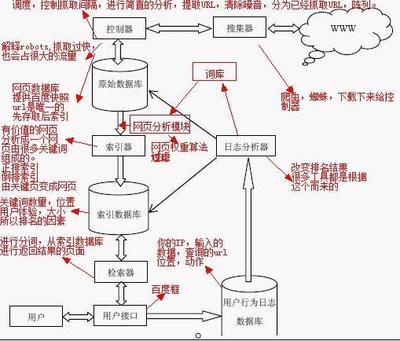
搜索引擎用来自动抓取网页的程序被称为蜘蛛,为了及时、快速、全面的收集互联网上的网页数据,SE会使用多个蜘蛛来抓取页面信息。蜘蛛抓取的流程如下:
1) 选取原始种子网页集合;
2) 爬行网页集合,把网页数据存入原始页面数据库,并抓取各个页面包含的超链接URL,形成新的网页集合;
3) 相关处理;
a.读取robots.txt进行判断那些网址被禁止;
b.判断URL是否存在已访问的链接库,并更新相关的链接库;
c.根据网页的更新频率,赋予相应的回访权值;
d.根据URL抓取权值,调整URL爬行的优先级;
e.简单的网页内容检测,判断复制内容;
f.URL重定向的处理。
4) 重复第2步骤;
2、 爬行策略主要三种:
5) 深度优先;
6) 广度优化;
7) 链接关系分析决定URL爬行顺序;
二、预处理
搜索引擎对抓取的原始页面主要进行网页内容分析与链接关系分析,以帮助建立好相关性索引,为查询服务做好准备,网页的最终排序得分有其内容相关度与链接分析结果线性加权而得到。
1、网页内容分析
网页分析包含提取可视化文本信息、分词、去除停用词、消除页面噪音、去掉重复的网页、倒排索引、正排索引、DF值处理,这些在ZAC的书都有详述;在这里想分享内容分析的相关算法模型:
1) 布尔模型
用于判读网页内容与查询的关键词是否相关,注意是判断是否相关而不是相关度。
2) 向量空间模型
以词汇为基向量构建一个N维空间,则网页就对应了N维空间的一个向量,根据向量之间的差别来判断网页内容的形似度。
3) P概率模型
根据关键词搜索引擎将网页分为相关/不相关类,相关类中各个词项具有相似的分布,不相关类中词项具有不同的分布,通过计算某网页W与已知相关/不相关网页词项分布相似性来衡量网页与查询的关键词的相关度。
4) 统计语言模型
根据词汇同时出现的概率统计来衡量网页数据质量的高低与度量网页与查询关键词的关系。
2、链接关系分析
链接关系分析是预处理中很重要的一部分,计算相应页面的网站和页面的链接权值;链接关系分析的基础是超链接页面之间的内容推荐与主题相关特性;链接分析算法包含HITS算法、PR算法、TR算法、Hilltop算法,这些在ZAC的书都有详述。
三、查询服务
搜索引擎对我们输入的词汇,进行分词处理,根据分词匹配相关网页,根据匹配网页的相关度高低赋予排名权值,再经过排名过滤后展现网页排名。
统计用户使用搜索引擎过程中相关数据来判读搜索结果的质量,以帮助调整搜索算法与提升对用户最有用的页面的排名。