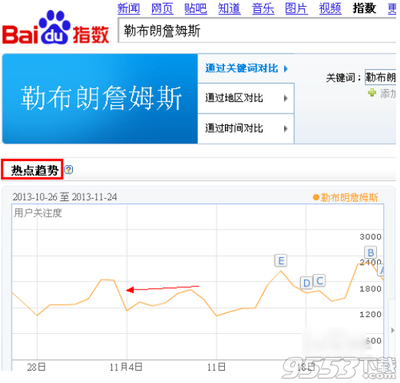
Snort中比较重要的全局变量
①_Packet结构体(位于decode.h文件):存储了所截获数据包的所有信息,包括数据包的类型,首部,数据内容等。
②_SnortConfig结构体:里面存储Snort各类配置文件的文件指针,记录各种运行模式的标识符,还定义了各种行为处理的链表。
③OptTreeNode,存储规则选项的链表
④RuleTreeNode,存储规则头的链表
⑤OTNX_MATCH_DATA结构体:存储了需要对数据包进行快速检测的信息。
⑥PORT_GROUP:存储不同类型要检测的规则结点;
主函数(SnortMain函数)流程分析
①调用初始化函数SnortInit();
②获得数据包,确定链路协议类型,调用GetPpacketSource
③注册控制处理器的句柄,调用ControlSocketRegisterHandler
④根据所选择的工作模式,初始化进程文件和权限操作
⑤调用解码函数SetPkPresessor
⑥ 循环抓包
SnortInit函数(功能为初始化Snort各项配置)流程分析
①解析命令行,调用ParseCmdLine函数
②根据选择的工作模式,输出相应信息
③注册输出模块、预处理模块、规则选项模块
④打印所有网卡、接口
⑤加载动态插件
Snort.h文件分析
此文件定义了配置文件信息的结构体,还有不同运行模式下的结构体信息,策略及工作模式的标识符,下面列出一些较重要的数据结构。
_PreprocConfig 结构体:存储预处理配置文件信息;
_OutputConfig结构体:存储输出插件的配置文件;_
DynamicLibInfo结构体:存储动态库的信息;
SnortPolicy结构体:存储Snort命令配置;
还有不同运行模式的结构体及其标识符,策略、输出标记;
在Snort里均是用链表来存储规则头和规则选项,并将一条规则的不同字段拆分出来,存到相应数据结构中:
①存储规则头的链表(RuleTreeNode)
这个结构体存储了当前规则的规则编号,规则所属类型,源/目的IP地址/端口的信息;再用RuleTreeNode类型的right指针指向下一个规则头,用OptTreeNode类型的down指针指向相应的规则选项;最后设置相应的输出队列,有Alert和log两种事件的输出队列;而每个处理行为都有一个链表来记录属于此类事件的规则;
②存储规则选项的结构体(OptTreeNode)
这个结构体存储了插件,数据包检测,输出插件的函数指针,日志记录的文件指针;指明了当前规则选项相关的规则头和下一条规则选项;
PacketCount记录数据包的收集信息 ,其中包括流过的数据包数目;
相应的snort.conf里创建用户自定义的规则集步骤是:
1) 设置网络变量 2)设置解码文件 3) 设置检测引擎 4) 设置动态加载库
5) 设置预处理器 6)设置输出插件 7) 自定义自己的规则集
8)自定义预处理和解码的规则集9) 自定义共享对象的规则集
Parse.c文件分析
功能:解析用户缩写规则,并将规则的不同字段填充到数据结构里。
在调用插件前,第一步是解析规则,填充到RTN的链表中来进行匹配,解析的实现在parse.c。
ParseConfigFile函数,读取用户每行的规则,存储到RTN中,再调用parseRule函数进一步解析;
parseRule函数:拆分我们所写的规则,将规则里面的每个字段调用不同函数填充到RTN里,新建端口变量表,解析端口链表,解析规则选项,并进行被解析规则的统计;
在Windows中调用PQ_XX等函数来抓包;获得包后,setPktProcessor函数:根据数据链路层协议类型,设置解码函数,然后解码函数指针保存在grinder中;
插件的初始化、注册源码分析
插件有分三类,一类是输出插件,一类是预处理插件,一类是检测插件。每次Snort都会先从Snort.conf里面读取开启了哪些插件,然后进行插件的注册、初始化;
Plugbase.h文件分析
功能:主要声明了Rule Option Plugin API
AddOptFuncToList函数将规则选项模块链接到OTN,对otn结构进行封装,实现了规则关键词及其处理函数的对应;AddRspFuncToList函数返回响应函数指针给链表;接下来就是对各种协议的解码,在decode.c中,具体实现在DecodeTCP,DecodeIP这类函数。
Plugbase.c文件分析
功能:做规则选项检测插件的初始化、注册,将RuleOptConfigFuncNode结构体里将规则插件名和对应的处理函数封装起来;负责封装的具体函数是RegisterRuleOption,把插件名与处理该规则选项的函数封装起来,用上图这个数据结构来存,keyword是插件名,而fptr是其实现函数的指针;
若我们要增添自己的编写的插件,在Plugin_enum.h里面添加,在Plugbase.c里引入自己编写的插件头文件(放在output文件夹里),并增添相应的注册函数PluginSetup();RegisterPlugin函数;
Output_base.h文件分析
输出插件的插件名与处理函数的封装,存储在在OutputConfigFuncNode里,插件注册函数是实现函数是RegisterOutputPlugin在plugbase.c文件里,_output_list_node这个数据结构存储以上这些节点的,具体注册函数的声明,在output_base.h文件内;
sf_dynamic_preprocessor.h文件分析
功能:定义了预处理器插件需要跟Snort交流数据时所用的接口。
主要定义了_DynamicPreprocessorData这个结构体的内容,注册插件时需初始化指向标准化后的字符串指针,标准化http,uri字符串的函数指针,填充各种处理函数的指针,如记录日志,预处理插件的报警,注册插件配置的插件名,将预处理插件封装到相应的数据结构里。
sf_dynamic_detect.h文件分析
功能:定义了检测模块与Snort交互的接口;具体的函数指针定义在_DynamicEngineData这个结构中;Dynamic规则的匹配要用到以下数据结构_Rule,_RuleInformation,_RuleReference,_IpInfo;其中_RuleOption包含了数据包内容搜索;
添加dynamic规则,首先编写一个规则文件,如同sid109.c文件所示,定义好FlowFlags,RuleOptions,ContentInfo,RuleReference这些结构体,定义出规则的内容;新建后的规则要在detection_lib_meta.c的rule结构体里添加;
预处理插件模块分析:
插件调用的流程是首先用预处理插件,以免某些攻击利用分片绕过引擎的检测;之后进行数据包检测。
预处理插件主要有以下:
一、异常检测预处理
SPP_sfportscan.c文件分析:
功能:负责端口扫描。
初始化包结构的缓冲区,我们在进行端口扫描的时候可以产生使IDS报警的数据包。
端口扫描主要做两件事:自己生成一数据包,复制网络层和传输层数据包的首部数据,再对开放的端口进行特定的数据包流监测。
关键函数如下:
MakeProtoInfo函数:功能是深度检测事件内容。其中,要检测的信息有:优先级数,协议同步号,和主机连接的IP号,所扫描的目标网络IP范围,发生了端口变化的主机端口号,端口号范围。接下来将地址号较大的地址号输出到缓冲区里,这样当我们多次用到inet_ntoa函数时重复打印相同地址,就可以省去每次拷贝inet_ntoa的结果这一步;
GenerateOpenPortEvent函数:只是用来跟踪开放端口,若有数据包进入端口,则做数据流的阀值测试;
MakePortscanPkt函数构建数据包,获取网络层与传输层数据包首部。构造的数据包类型按照用户要检测的数据包类型一样。
PortscanAlertXXX之类的函数:端口扫描时对流过的XX协议数据包进行记录报警
二、包重组预处理器
Stream5common.c文件分析:
功能:声明存储不同协议会话组重组的结构体及函数
存储的数据结构为Stream5Config,里面的成员变量存储IP/UDP/TCP/ICMP协议的内容配置;
三、IP分片和攻击检测
IP分片检测:首先用_Frag3Context存储要被检测的信息,其中的成员frag3_alert标识是否对分片攻击进行报警检测,如果是,设置事件监听,并根据不同的情况,对需报警、有异常的数据包统计个数。
Spp_arpspoof.c文件分析:功能:ARP欺骗检测。
检测模块分析
Detect.c定义检测模块的函数,数据结构有:RuleListNode, RuleTreeNode, PORT_GROUP, OTNX_MATCH_DATA,ListHead,首先匹配规则前将相应的处理函数链接到相应的规则节点,RuleTreeNode节点存着每个规则节点的信息,还有相应的处理函数在RuleFpList存放。Snort并不是一条条遍历按顺序规则里的每个词,Snort先断开关键词,将数据包按协议分类,然后在相应协议的规则子集合里面匹配;Snort的规则被分为2部分,一个规则头,用RTN结构体来存储,一个规则选项,用OTN结构体来存储,而快速检测的OTNX结构体中存储了OTN类型的域,这样检测规则的时候就还是到RTN和OTN里面匹配了。
因为网络数据包较多,Snort先分端口组,按照数据包所属类型在规则的子集合里匹配,规则子集合里,又按照content,uri-content, nocontent规则节点进行遍历匹配;
数据包检测模块分析:
Fpcreate.c文件分析
首先,建立规则快速匹配的模型: fpCreateFastPacketDetection创建了以下内容:①端口组②检测规则表 ③服务-端口组表
建立每个服务与其规则选项的映射表,存放的数据结构为srmm_table_t,
ServiceMapAddOtnRaw函数是建立一个服务名和规则的表格,使用者可以给当前服务添加规则;
ServiceMapAddOtn程序会创建一个服务表格,这表格包含了协议及服务所在路径;而每个规则列表根据服务名来映射到表格中相应的服务;
prmFindRuleGroupIP这类函数是给待测数据包进行分类,然后调用prmFindRuleGroup函数,查找到待测数据包的规则集;
检测模块匹配规则的数据结构主要为OTNX_MATCH_DATA:首先PORT_GROUP是规则集;check_ports是用来判断是否检测端口的,MATCH_INFO是存储在规则匹配下的某种事件的相关信息,iMathcInfoArraySize是规则类型数量;iMatchMaxLen是匹配规则中的最长长度,这个变量通常会在匹配规则时根据当前最长的规则而更新长度;iMatchCount是匹配的次数;
对OTNX结构体的处理函数如下:
①fpEvalPacket:对不同数据包进行分类,并调用fpEvalHeaderXX函数来进行检测;若有ipv6的单播数据包,用UDP数据报的规则集合检测;
②fpEvalHeaderSW,将数据包重新构建,再检测数据包内容,并根据传入参数判定是否检测源端口、目的端口的数据包内容;检测有3项:URI的内容检测,数据包内容与规则的匹配,(这两个的检测方法是mpsSearch),no-content的规则节点遍历;
③fpEvalHeaderUDP之类的函数,用UDP数据包的规则集合进行检测,并调用设置该数据包的行为处理函数,除此之外,对ICMP包,IP包,TCP包也是类似处理;
④fpEvalRTN查找有没有符合数据包的规则头检测规则,有则返回1;实现过程是:遍历检测函数列表进行规则头的检测。
检测完成之后,会由fpFinalSelectEvent将队列里的事件都输出,其中调用SnortEventqAdd进行事件添加;
fpAddMatch将事件分类、加入匹配的队列(Alert,log,pass),对于一个包,可以让它触发多种事件,存储检测事件的相关信息到omd里;
输出插件里有LogList和AlertList两个链表,当触发Log或者Alert事件时,就会从这两个链表里输出信息;
日志记录模块分析
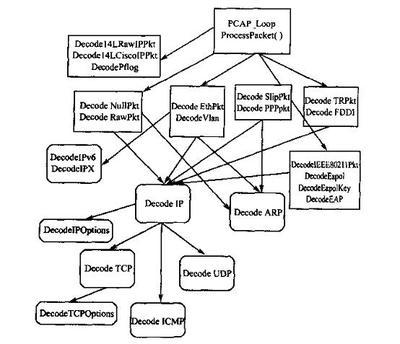
Event_queue.c文件分析:
功能:日志记录;
关键函数:LogSnortEvent函数。
此函数的调用层次是LogSnortEevent->fpLogEvent->ActiveAction/Active_queue等检测是否触发事件记录的函数->CallLogFunc等记录函数