数据库内容丰富,蕴藏大量信息,可以用来作出智能的商务决策。分类和预测是两种数据分析形势,可以用于提取描述重要数据类的模型和预测未来的数据趋势。
数据分类(dataclassfication)是一个两步过程。第一步,建立一个模型,描述预定的数据类集或概念集。通过分析由属性描述的数据库元组来构造模型。假定每个元组属于一个预定义的类,由一个称作类标号属性(classlabelatrribute)的属性确定。对于分类,数据元组也称作样本、实例或对象。为模型建立而被分析的数据元组形成训练数据集。训练数据集中的单个元组称作训练样本,并随机地由样本群选取。由于提供了每个训练样本的类标号,该步也称作有指导的学习(即模型的学习在被告知每个训练样本属于哪个类的“指导”下进行)。它不同于无指导的学习,那里每个训练样本的类标号是未知的,要学习的类集合或数量也可能事先不知道。
第二步,使用模型进行分类。首先评估模型的预测准确率。如果模型的准确率根据训练数据集评估,评估的结果可能是乐观的。因此,我们需要选择独立于训练集的测试样本集去评估模型的准确率。如果认为模型的准确率可以接受,就可以用它对类标号未知的数据元组或对象进行分类。
分类和预测具有很广泛的应用,包括信誉证实、医疗诊断、性能预测和选择购物等。以下介绍一种数据分类的基本技术,决策树分类模型。
1.什么是决策树
1.1决策树的定义:
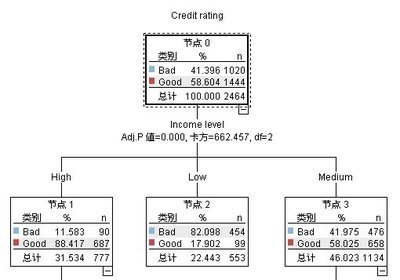
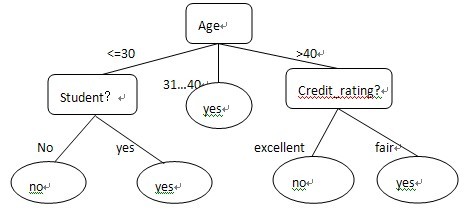
决策树(decisiontree)是一个类似于流程图的树结构,其中每个内部节点表示子在一个属性上的测试,每个分枝代表一个测试输出,而每个树节点代表类或者类分布。树的最顶层节点是根节点。我们可以用下图表示一颗典型的决策树模型。以下这颗决策树用来预测顾客是否可能购买计算机。
通过以上决策树示例可以得出几组规则,其中一组为:“Age<=30”且“不是student”,则可以推测出:该顾客不可能购买计算机。决策树很容易转换成分类规则。
1.2决策树的特点:
决策树算法本身的特点使其适合进行属性数(特征数)较少情况下的高质量分类,因而适用于仅仅利用主题无关特征进行学习的关键资源定位任务。
决策树算法的核心问题是选取在树的每个结点即要测试的属性,争取能够选择出最有助于分类实例的属性.为了解决这个问题,ID3算法引入了信息增益的概念,并使用信息增益的多少来决定决策树各层次上的不同结点即用于分类的重要属性。
1.3决策树的优缺点:
优点:1)可以生成可以理解的规则。
2)计算量相对来说不是很大。
3)可以处理多种数据类型。
4)决策树可以清晰的显示哪些字段较重要。
缺点:1)对连续性的字段比较难预测。
2)有时间顺序的数据,要很多预处理工作。
3)当类别太多时,错误可能就会增加较快。
2.决策树经典算法ID3介绍
早期著名的决策树算法是1986年由Quinlan提出的ID3算法。ID3算法运用信息熵理论,选择当前样本集中最大信息增益的属性值作为测试属性;样本集的划分则依据测试属性的值进行,测试属性有多少不同取值就将样本集划分为多少子样本集,同时,决策树上相应于该样本集的节点长出新的叶子节点。由于决策树的结构越简单越能从本质的层次上概括事物的规律,期望非叶节点到达后代节点的平均路径总是最短,即生成的决策树的平均深度最小,这就要求在每个节点选择好的划分。
ID3算法的基本原理如下:该算法是一种贪心算法,它以自顶向下递归的各个击破方式构造决策树。算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性。对测试属性的每个已知的值,创建一个分枝,并据此划分样本。这种信息理论方法使得一个对象分类所需的期望测试数目达到最小,并确保找到一颗简单的树。计算每个属性的信息增益值的方法如下:
设S是s个数据样本的集合。假定类标号属性具有m个不同值,定义m个不同类Ci(i=1,…m)。设si是类Ci中的样本数。对一个给定的样本分类所需的期望信息由下式给出:
I(S1,S2,…Sm)iLog2(pi),公式(1)
,其中Pi是任意样本属于Ci的概率,并用si/s估计。
又设属性A具有v个不同值{a1,a2,…av}。可以用属性A将S划分为V个子集{S1,S2,…SV};其中,Sj包含S中这样一些样本,它们在A上具有值aj。Sij是子集Sj中类Ci的样本数。根据由A划分子集的熵或期望信息由下式给出:
E(A)= I(s1j,…smj),公式(2)
由(1)和(2)式,得出在A上分支的信息增益为:
Gain(A)=I(s1,s2,…sm)-E(A)
ID3选择gain(A)最大,也就是E(A)最小的属性A作为根结点,决策树建好后,就可以生成许多规则:类似if…then…知识规则。系统根据测试内节点的值,推断出相关规则。