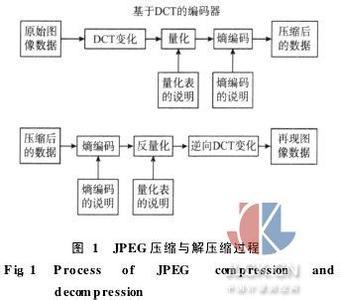
一.香农-范诺编码 < XMLNAMESPACE PREFIX ="O"/>
香农-范诺(Shannon-Fano)编码的目的是产生具有最小冗余的码词(codeword)。其基本思想是产生编码长度可变的码词。码词长度可变指的是,被编码的一些消息的符号可以用比较短的码词来表示。估计码词长度的准则是符号出现的概率。符号出现的概率越大,其码词的长度越短。
香农-范诺编码算法需要用到下面两个基本概念:
(1)熵(Entropy)
某个事件的信息量(又称自信息)用
Ii= -log2pi
表示,其中pi为第i个事件的概率,0<pi ≤ 1。
信息量Ii的概率平均值叫做信息熵,或简称熵。
熵是信息量的度量方法,它表示某一事件出现的消息越多,事件发生的可能性就越小,数学上就是概率越小。
(2)信源的熵
按照香农的理论,信源S的熵定义为
< XMLNAMESPACE PREFIX ="V"/>
其中pi是符号Si在S中出现的概率;log2(1/pi)表示包含在Si中的信息量,也就是编码Si所需要的位数。
按照香农的理论,熵是平稳信源的无损压缩效率的极限。例如,一幅用256级灰度表示的图像,如果每一个像素点灰度的概率均为pi=1/256,编码每一个像素点就需要8位(比特,bit)。
香农-范诺编码算法步骤:
(1)按照符号出现的概率减少的顺序将待编码的符号排成序列。
(2)将符号分成两组,使这两组符号概率和相等或几乎相等。
(3)将第一组赋值为0,第二组赋值为1。
(4)对每一组,重复步骤2的操作。
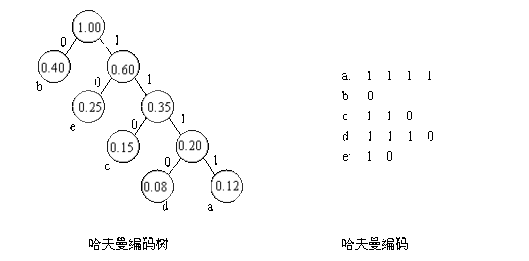
下面我们用一个例子说明。假定有下述内容:
"EXAMPLE OF SHANNON FANO"
首先,我们计算文本中每个符号出现的概率,见表3-03。
然后,按照按照符号概率排成序列:
'N ','','O','A','E','F','X','M','P','L','S','H'
将'N','','O','A'编为一组,赋值为0;其余的为另一组,赋值为1。递归下去,如图03-02-1所示。
表03-02-1符号在文本中出现的概率
符号 | 概率 |
E | 2/23 |
X | 1/23 |
A | 3/23 |
M | 1/23 |
P | 1/23 |
L | 1/23 |
O | 3/23 |
F | 2/23 |
S | 1/23 |
H | 1/23 |
N | 4/23 |
空格 | 3/23 |
在我们的例子中有23个字符的文本中共有12个符号。用4个比特才能表示12个符号,编码这个文本需要4x23=92个比特。按照香农理论,这个文本的熵为
H(S) =(2/23)log2(23/2)+(1/23)log2(23/1)+…+(3/23)log2(23/3)
= 2.196
这就是说每个符号用2.196比特表示可以,23个字符需用87.84比特。
图03-02-1香农-范诺算法编码例
由于上述理论是香农(ClaudeShannon,1948年)和范诺(RobertFano,1949年)各自独立发现的,因此被称为香农-范诺算法。香农-范诺的理论虽然指出了平稳信源的无损压缩的极限,实际的问题在于,为了达到这个极限,通常需要建立一种对于n字信源的编码,当n很大时,这样的编码不但很复杂,而且会导致一般系统无法容忍的延时。实际上,人们通常不采用压缩到熵率的无损编码。他们宁愿采用准优化的压缩方式以求可操作性和低延时。3类和4类传真标准就是例子,它们在实际无损压缩过程中牺牲了一点压缩效率以提高可实现性和灵活性。霍夫曼编码则是另一个改进的例子。
二.霍夫曼编码
霍夫曼(Huffman)编码属于码词长度可变的编码类,是霍夫曼在1952年提出的一种编码方法,即从下到上的编码方法。同其他码词长度可变的编码一样,可区别的不同码词的生成是基于不同符号出现的不同概率。生成霍夫曼编码算法基于一种称为“编码树”(codingtree)的技术。算法步骤如下:
(1)初始化,根据符号概率的大小按由大到小顺序对符号进行排序。
(2)把概率最小的两个符号组成一个新符号(节点),即新符号的概率等于这两个符号概率之和。
(3)重复第2步,直到形成一个符号为止(树),其概率最后等于1。
(4)从编码树的根开始回溯到原始的符号,并将每一下分枝赋值为1,上分枝赋值为0。
以下这个简单例子说明了这一过程。
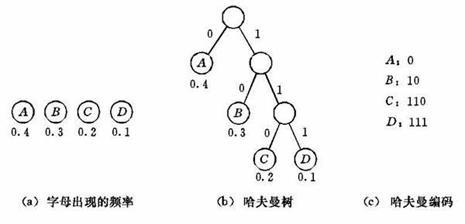
1).字母A,B,C,D,E已被编码,相应的出现概率如下:
p(A)=0.16,p(B)=0.51, p(C)=0.09,p(D)=0.13, p(E)=0.11
2).C和E概率最小,被排在第一棵二叉树中作为树叶。它们的根节点CE的组合概率为0.20。从CE到C的一边被标记为1,从CE到E的一边被标记为0。这种标记是强制性的。所以,不同的哈夫曼编码可能由相同的数据产生。
3).各节点相应的概率如下:
p(A)=0.16, p(B)=0.51,p(CE)=0.20, p(D)=0.13
D和A两个节点的概率最小。这两个节点作为叶子组合成一棵新的二叉树。根节点AD的组合概率为0.29。由AD到A的一边标记为1,由AD到D的一边标记为0。
如果不同的二叉树的根节点有相同的概率,那么具有从根到节点最短的最大路径的二叉树应先生成。这样能保持编码的长度基本稳定。
4).剩下节点的概率如下:
p(AD)=0.29,p(B)=0.51, p(CE)=0.20
AD和CE两节点的概率最小。它们生成一棵二叉树。其根节点ADCE的组合概率为0.49。由ADCE到AD一边标记为0,由ADCE到CE的一边标记为1。
5).剩下两个节点相应的概率如下:
p(ADCE)=0.49,p(B)=0.51
它们生成最后一棵根节点为ADCEB的二叉树。由ADCEB到B的一边记为1,由ADCEB到ADCE的一边记为0。
6).图03-02-2为霍夫曼编码。编码结果被存放在一个表中:
w(A)=001, w(B)=1,w(C)=011, w(D)=000,w(E)=010
图03-02-2霍夫曼编码例
霍夫曼编码器的编码过程可用例子演示和解释。
下面是另一个霍夫曼编码例子。假定要编码的文本是:
"EXAMPLE OF HUFFMAN CODE"
首先,计算文本中符号出现的概率(表03-02-2)。
表03-02-2符号在文本中出现的概率
符号 | 概率 |
E | 2/25 |
X | 1/25 |
A | 2/25 |
M | 2/25 |
P | 1/25 |
L | 1/25 |
O | 2/25 |
F | 2/25 |
H | 1/25 |
U | 1/25 |
C | 1/25 |
D | 1/25 |
I | 1/25 |
N | 2/25 |
G | 1/25 |
空格 | 3/25 |
最后得到图03-02-3所示的编码树。
图03-02-3霍夫曼编码树
在霍夫曼编码理论的基础上发展了一些改进的编码算法。其中一种称为自适应霍夫曼编码(AdaptiveHuffman code)。这种方案能够根据符号概率的变化动态地改变码词,产生的代码比原始霍夫曼编码更有效。另一种称为扩展的霍夫曼编码(ExtendedHuffman code)允许编码符号组而不是单个符号。
同香农-范诺编码一样,霍夫曼码的码长虽然是可变的,但却不需要另外附加同步代码。这是因为这两种方法都自含同步码,在编码之后的码串中都不需要另外添加标记符号,即在译码时分割符号的特殊代码。当然,霍夫曼编码方法的编码效率比香农-范诺编码效率高一些。
采用霍夫曼编码时有两个问题值得注意:①霍夫曼码没有错误保护功能,在译码时,如果码串中没有错误,那么就能一个接一个地正确译出代码。但如果码串中有错误,那怕仅仅是1位出现错误,也会引起一连串的错误,这种现象称为错误传播(errorpropagation)。计算机对这种错误也无能为力,说不出错在哪里,更谈不上去纠正它。②霍夫曼码是可变长度码,因此很难随意查找或调用压缩文件中间的内容,然后再译码,这就需要在存储代码之前加以考虑。尽管如此,霍夫曼码还是得到广泛应用。