方差分析是用于两个及两个以上样本均数差别的显著性检验。由于各种因素的影响,研究所得的数据呈现波动状,造成波动的原因可分成两类,一是不可控的随机因素,另一是研究中施加的对结果形成影响的可控因素。方差分析的基本思想是:通过分析研究不同来源的变异对总变异的贡献大小,从而确定可控因素对研究结果影响力的大小。
方差分析主要用途:①均数差别的显著性检验,②分离各有关因素并估计其对总变异的作用,③分析因素间的交互作用,④方差齐性检验。
在科学实验中常常要探讨不同实验条件或处理方法对实验结果的影响。通常是比较不同实验条件下样本均值间的差异。例如医学界研究几种药物对某种疾病的疗效;农业研究土壤、肥料、日照时间等因素对某种农作物产量的影响;不同化学药剂对作物害虫的杀虫效果等,都可以使用方差分析方法去解决。
方差分析原理
方差分析的基本原理是认为不同处理组的均数间的差别基本来源有两个:
(1) 随机误差,如测量误差造成的差异或个体间的差异,称为组内差异,用变量在各组的均值与该组内变量值之偏差平方和的总和表示, 记作SSw,组内自由度dfw。
(2) 实验条件,实验条件,即不同的处理造成的差异,称为组间差异。用变量在各组的均值与总均值之偏差平方和表示,记作SSb,组间自由度dfb。
总偏差平方和 SSt = SSb + SSw。
组内SSt、组间SSw除以各自的自由度(组内dfw =n-m,组间dfb=m-1,其中n为样本总数,m为组数),得到其均方MSw和MSb,一种情况是处理没有作用,即各组样本均来自同一总体,MSb/MSw≈1。另一种情况是处理确实有作用,组间均方是由于误差与不同处理共同导致的结果,即各样本来自不同总体。那么,MSb>>MSw(远远大于)。
MSb/MSw比值构成F分布。用F值与其临界值比较,推断各样本是否来自相同的总体。 方差分析的假设检验
假设有m个样本,如果原假设H0:样本均数都相同即μ1=μ2=μ3=„=μm=μ,m个样本有共同的方差。则m个样本来自具有共同的方差和相同的均数u的总体。
零假设H0:m组样本均值都相同,即μ1= μ2=....= μm
如果,计算结果的组间均方远远大于组内均方(MSb>>MSw),F>F0.05(dfb,dfw), p0.05不能拒绝零假设,说明样本来自相同的正态总体,处理间无差异。
SPSS中方差分析过程
1)One-Way ANOVA过程
One-Way过程是单因素简单方差分析过程。它在Analyze菜单中的Compare Means过程组中。用0ne-Way ANOVA菜单项调用,可以进行单因素方差分析、均值多重比较和相对比较。
2)General Linear Model 过程组
在SPSS主菜单“Analyze”项调用。这些过程可以完成简单的多因素方差分析和协方差分析,不但可以分析各因素的主效应,还可以分析各因素间的交互效应。该过程允许指定最高阶次的交互效应,建立包括所有效应的模型。如果想建立包括某些特定的交互效应的模型也可以通过过程中的“Method”对话框中的选择项实现。
在General Linear Model菜单项的下一级菜单中有四项过程,每个菜单项分别完成不同类型的方差分析任务。这些过程的主要功能分别是:
① Univariate 过程
Univariate过程完成一般的单因变量、多因素方差分析。可以指定协变量,即进行协方差分析。在指定模型方面有较大的灵活性并可以提供大量的统计输出。
② Multivariate过程
Multivariate过程进行多因变量的多因素分析。当研究的问题具有两个或两个以上相关的因变量时,要研究一个或几个因素变量与因变量集之间的关系时,才可以选用
Multivariate过程。例如,当你研究数学、物理的考试成绩是否与教学方法、学生性别、以及方法与性别的交互作用有关时,使用此菜单项。如果只有几个不相关的因变量或只有一个因变量,应该使用Univariate过程。
③ Repeated Measure过程
Repeated Measure过程进行重复测量方差分析。当一个因变量在不只一种条件下进行测度,要检验有关因变量均值的假设应该使用该过程。
④ Variance Component 过程
Variance Component过程进行方差估计分析。通过计算方差估计值,可以帮助我们分析如何减小方差。
单因素方差分析
单因素方差分析也称作一维方差分析。它检验由单一因素影响的一个(或几个相互独立的)因变量由因素各水平分组的均值之间的差异是否具有统计意义。还可以对该因素的若干水平分组中哪一组与其他各组均值间具有显著性差异进行分析,即进行均值的多重比较。One-Way ANOVA过程要求因变量属于正态分布总体。如果因变量的分布明显的是非正态,不能使用该过程,而应该使用非参数分析过程。如果几个因变量之间彼此不独立,应该用Repeated Measure过程。
[例子]
调查不同水稻品种百丛中稻纵卷叶螟幼虫的数量,数据如表5-1所示。
表5-1 不同水稻品种百丛中稻纵卷叶螟幼虫数
数据保存在“DATA5-1.SAV”文件中,变量格式如图5-1。
图5-1
分析水稻品种对稻纵卷叶螟幼虫抗虫性是否存在显著性差异。
1)准备分析数据
在数据编辑窗口中输入数据。建立因变量“幼虫”和因素水平变量“品种”,然后输入对应的数值,如图5-1所示。或者打开已存在的数据文件“DATA5-1.SAV”。
2)启动分析过程
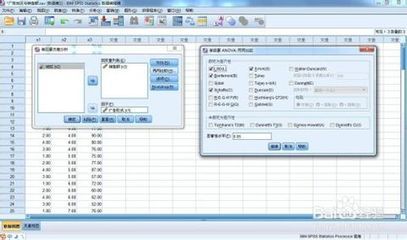
点击主菜单“Analyze”项,在下拉菜单中点击“Compare Means”项,在右拉式菜单中点击“0ne-Way ANOVA”项,系统
打开单因素方差分析设置窗口如图5-2。
图5-2 单因素方差分析窗口
3)设置分析变量
因变量: 选择一个或多个因子变量进入“Dependent List”框中。本例选择“幼虫”。 因素变量: 选择一个因素变量进入“Factor”框中。本例选择“品种”。
4)设置多项式比较
单击“Contrasts”按钮,将打开如图5-3所示的对话框。该对话框用于设置均值的多项式比较。
图5-3 “Contrasts”对话框
定义多项式的步骤为:
均值的多项式比较是包括两个或更多个均值的比较。例如图5-3中显示的是要求计算“1.1×mean1-1×mean2”的值,检验的假设H0:第一组均值的1.1倍与第二组的均值相等。单因素方差分析的“0ne-Way ANOVA”过程允许进行高达5次的均值多项式比较。多项式的系数需要由读者自己根据研究的需要输入。具体的操作步骤如下:
① 选中“Polynomial”复选项,该操作激活其右面的“Degree”参数框。
② 单击Degree参数框右面的向下箭头展开阶次菜单,可以选择“Linear”线性、“Quadratic”二次、“Cubic”三次、“4th”四次、“5th”五次多项式。
③ 为多项式指定各组均值的系数。方法是在“Coefficients”框中输入一个系数,单击Add按钮,“Coefficients”框中的系数进入下面的方框中。依次输入各组均值的系数,在方形显示框中形成—列数值。因素变量分为几组,输入几个系数,多出的无意义。如果多项式中只包括第一组与第四组的均值的系数,必须把第二个、第三个系数输入为0值。如果只包括第一组与第二组的均值,则只需要输入前两个系数,第三、四个系数可以不输入。 可以同时建立多个多项式。一个多项式的一组系数输入结束,激话“Next”按钮,单击该按钮后“Coefficients”框中清空,准备接受下一组系数数据。
如果认为输入的几组系数中有错误,可以分别单击“Previous”或“Next”按钮前后翻找出错的一组数据。单击出错的系数,该系数显示在编辑框中,可以在此进行修改,修改后单击“Change”按钮在系数显示框中出现正确的系数值。当在系数显示框中选中一个系数时,同时激话“Remove”按钮,单击该按钮将选中的系数清除。
④单击“Previous”或“Next”按钮显示输入的各组系数检查无误后,按
“Continue”按钮确认输入的系数并返回到主对话框。要取消刚刚的输入,单击“Cancel”按钮;需要查看系统的帮助信息,单击“Help”按钮。
本例子不做多项式比较的选择,选择缺省值。
5)设置多重比较
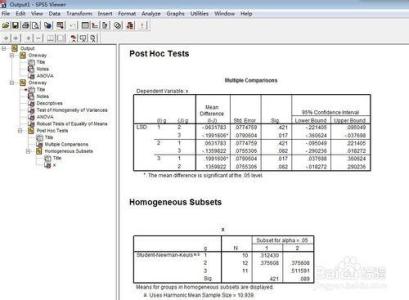
在主对话框里单击“Post Hoc”按钮,将打开如图5-4所示的多重比较对话框。该对话框用于设置多重比较和配对比较。方差分析一旦确定各组均值间存在差异显著,多重比较检测可以求出均值相等的组;配对比较可找出和其它组均值有差异的组,并输出显著性水平为0.95的均值比较矩阵,在矩阵中用星号表示有差异的组。
图5-4 “Post Hoc Multiple Comparisons”对话框
(1)多重比较的选择项:
①方差具有齐次性时(Equal Variances Assumed),该矩形框中有如下方法供选择:
LSD (Least-significant difference) 最小显著差数法,用t检验完成各组均值间的配对比较。对多重比较误差率不进行调整。
Bonferroni (LSDMOD) 用t检验完成各组间均值的配对比较,但通过设置每个检验的误差率来控制整个误差率。
Sidak 计算t统计量进行多重配对比较。可以调整显著性水平,比Bofferroni方法的界限要小。
Scheffe 对所有可能的组合进行同步进入的配对比较。这些选择项可以同时选择若干个。以便比较各种均值比较方法的结果。
R-E-G-WF (Ryan-Einot-Gabriel-Welsch F) 用F检验进行多重比较检验。
R-E-G-WQ (Ryan-Einot-Gabriel-Welsch range test) 正态分布范围进行多重配对比较。
S-N-K (Student-Newmnan-Keuls) 用Student Range分布进行所有各组均值间的配对比较。如果各组样本含量相等或者选择了
“Harmonic average of all groups”即用所有各组样本含量的调和平均数进行样本量估计时还用逐步过程进行齐次子集(差异较
小的子集)的均值配对比较。在该比较过程中,各组均值从大到小按顺序排列,最先比较最末端的差异。
Tukey (Tukey's,honestly signicant difference) 用Student-Range统计量进行所有组间均值的配对比较,用所有配对比较误
差率作为实验误差率。
Tukey's-b 用“stndent Range”分布进行组间均值的配对比较。其精确值为前两种检验相应值的平均值。
Duncan (Duncan's multiple range test) 新复极差法(SSR),指定一系列的“Range”值,逐步进行计算比较得出结论。
Hochberg's GT2 用正态最大系数进行多重比较。
Gabriel 用正态标准系数进行配对比较,在单元数较大时,这种方法较自由。
Waller-Dunca 用t统计量进行多重比较检验,使用贝叶斯逼近。
Dunnett 指定此选择项,进行各组与对照组的均值比较。默认的对照组是最后一组。选择了该项就激活下面的“Control
Category”参数框。展开下拉列表,可以重新选择对照组。
“Test”框中列出了三种区间分别为: “2-sides” 双边检验; “Conbo1”“右边检验。
②方差不具有齐次性时(Equal Varance not assumed),检验各均数间是否有差异的方祛有四种可供选择:
Tamhane's T2, t检验进行配对比较。
Dunnett's T3,采用基于学生氏最大模的成对比较法。
Games-Howell,Games-Howell比较,该方法较灵活。
Dunnett's C,采用基于学生氏极值的成对比较法。
③ Significance 选择项,各种检验的显著性概率临界值,默认值为0.05,可由用户重新设定。
本例选择“LSD”和“Duncan”比较,检验的显著性概率临界值0.05。
6) 设置输出统计量
单击“Options”按钮,打开“Options”对话框,如图5-5所示。选择要求输出的统计量。并按要求的方式显示这些统计量。在该对话框中还可以选择对缺失值的处理要求。各组选择项的含义如下:
图5-5输出统计量的设置
“Statistics”栏中选择输出统计量:
Descriptive,要求输出描述统计量。选择此项输出观测量数目、均值、标准差、标准误、最小值、最大值、各组中每个因变量
的95%置信区间。
Fixed and random effects, 固定和随机描述统计量
Homogeneity-of-variance,要求进行方差齐次性检验,并输出检验结果。用“Levene lest ”检验,即计算每个观测量与其组均
值之差,然后对这些差值进行一维方差分析。
Brown-Forsythe 布朗检验
Welch,韦尔奇检验
Means plot,即均数分布图,根据各组均数描绘出因变量的分布情况。
“Missing Values”栏中,选择缺失值处理方法。
Exclude cases analysis by analysis选项,被选择参与分析的变量含缺失值的观测量,从分析中剔除。
Exclude cases listwise选项,对含有缺失值的观测量,从所有分析中剔除。
以上选择项选择完成后,按“Continue”按钮确认选择并返回上一级对话框;单击“Cancel”按钮作废本次选择;单击“Help”按钮,显示有关的帮助信息。
本例子选择要求输出描述统计量和进行方差齐次性检验,缺失值处理方法选系统缺省设置。
6)提交执行
设置完成后,在单因素方差分析窗口框中点击“OK”按钮,SPSS就会根据设置进行运算,并将结算结果输出到SPSS结果输出窗口中。
7) 结果与分析
输出结果:
表5-2描述统计量,给出了水稻品种分组的样本含量N、平均数Mean、标准差
Std.Deviation、标准误Std.Error、95%的置信区间、最小值和最大值。
表5-3为方差齐次性检验结果,从显著性慨率看,p>0.05,说明各组的方差在a=0.05水平上没有显著性差异,即方差具有齐次性。这个结论在选择多重比较方法时作为一个条件。
表5-4方差分析表:第1栏是方差来源,包括组间变差“Between Groups”;组内变差“Within Groups”和总变差“Total”。第2栏是离差平方和“Sum of Squares”,组间离差平方和87.600,组内离差平方和为24.000,总离差平方和为111.600,是组间离差平方和与组内离差平方和相加之和。第3栏是自由度df,组间自由度为4,组内自由度为10;总自由度为14。第4栏是均方“Mean Square”,是第2栏与第3栏之比;组间均方为21.900,组内均方为2.400。第5栏是F值9.125(组间均方与组内均方之比)。第6栏:F值对应的概率值,针对假设H0:组间均值无显著性差异(即5种品种虫数的平均值无显著性差异)。计算的F值9.125,对应的概率值为0.002。
表5-5 LSD法进行多重比较表,从表5-4结论已知该例子的方差具有其次性,因此LSD方法适用。第1栏的第1列“[i]品种”为比较基准品种,第2列“[j]品种”是比较品种。第2栏是比较基准品种平均数减去比较品种平均数的差值(Mean Difference),均值之间具有0.05水平(可图5-4对话框里设置)上有显著性差异,在平均数差值上用“*”号表明。第3栏是差值的标准误。第4栏是差值检验的显著性水平。第5栏是差值的95%置信范围的下限和上限。
表5-6 是多重比较的Duncan法进行比较的结果。第1栏为品种,按均数由小到大排列。第2栏列出计算均数用的样本数。第3栏列出了在显著水平0.05上的比较结果,表的最后一行是均数方差齐次性检验慨率水平,p>0.05说明各组方差具有齐次性。
多重比较比较表显著性差异差异的判读:在同一列的平均数表示没有显著性差异,反之则具有显著性的差异。例如,品种3横向看,平均数显示在第3列“2”小列,与它同列显示的有品种2的平均数,说明与品种2差异不显著(0.05水平),再往右看,平均数显示在第3列“3”小列,与它同列显示的有品种4的平均数,说明与品种4差异不显著(0.05水平)。则品种3与品种5和品种1具有显著性的差异(0.05水平)。
品种3和品种4都显示有平均数值。
结果分析:
根据方差分析表输出的p值为0.002可以看出,无论临界值取0.05,还是取0.01,p值均小于临界值。因此否定Ho假设,水稻品种对稻纵卷叶螟幼虫抗虫性有显著性意义,结论是稻纵卷叶螟幼虫数量的在不同品种间有明显的不同。根据该结论选择抗稻纵卷叶螟幼虫水稻品种,犯错误的概率几乎为0.008。
只有在方差分析中F检验存在差异显著性时,才有比较的统计意义。
LSD法多重比较表明:
品种1与品种2、品种3和品种5之间存在显著性差异;
品种2与品种1和品种4之间存在显著性差异;
品种3与品种1和品种5之间存在显著性差异;
品种4与品种2和品种5之间存在显著性差异;
品种5与品种1、品种3和品种4之间存在显著性差异。
Duncan法多重比较表明:
品种5与品种3、品种4和品种1之间存在显著性差异。
品种2与品种4和品种1之间存在显著性差异;
品种3与品种5和品种1之间存在显著性差异;
品种4与品种5和品种2之间存在显著性差异;
品种1与品种5、品种2和品种3之间存在显著性差异;
两种方法比较结果一致。
多因素方差分析
多因素方差分析是对一个独立变量是否受一个或多个因素或变量影响而进行的方差分析。SPSS调用“Univariate”过程,检验不同水平组合之间因变量均数,由于受不同因素影响是否有差异的问题。在这个过程中可以分析每一个因素的作用,也可以分析因素之间的交互作用,以及分析协方差,以及各因素变量与协变量之间的交互作用。该过程要求因变量是从多元正态总体随机采样得来,且总体中各单元的方差相同。但也可以通过方差齐次性检验选择均值比较结果。因变量和协变量必须是数值型变量,协变量与因变量不彼此独立。因素变量是分类变量,可以是数值型也可以是长度不超过8的字符型变量。固定因素变量(Fixed Factor)是反应处理的因素;随机因素是随机地从总体中抽取的因素。
[例子]
研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异。
表5-7 不同温度与不同湿度粘虫发育历期表
数据保存在“DATA5-2.SAV”文件中,变量格式如图5-1。
1)准备分析数据
在数据编辑窗口中输入数据。建立因变量历期“历期”变量,因素变量温度“A”,湿度为“B”变量,重复变量“重复”。然后输入对应的数值,如图5-6所示。或者打开已存在的数据文件“DATA5-2.SAV”。
图5-6 数据输入格式
2)启动分析过程
点击主菜单“Analyze”项,在下拉菜单中点击“General Linear Model”项,在右拉式菜单中点击“Univariate”项,系统打开单因变量多因素方差分析设置窗口如图5-7。
图5-7 多因素方差分析窗口
3)设置分析变量
设置因变量: 在左边变量列表中选“历期”,用
Variable:”框中。 向右拉按钮选入到“Dependent
设置因素变量: 在左边变量列表中选“a”和“b”变量,用向右拉按钮移到
“Fixed Factor(s):”框中。可以选择多个因素变量。由于内存容量的限制,选择的因素水平组合数(单元数)应该尽量少。
设置随机因素变量: 在左边变量列表中选“重复”变量,用向右拉按钮移到“到Random Factor(s)”框中。可以选择多个随机变量。
设置协变量:如果需要去除某个变量对因素变量的影响,可将这个变量移到
“Covariate(s)”框中。
设置权重变量:如果需要分析权重变量的影响,将权重变量移到“WLS Weight”框中。
4)选择分析模型
在主对话框中单击“Model”按钮,打开“Univariate Model”对话框。见图5-8。
图5-8 “Univariate Model” 定义分析模型对话框
在Specify Model栏中,指定分析模型类型。
① Full Factorial选项
此项为系统默认的模型类型。该项选择建立全模型。全模型包括所有因素变量的主效应和所有的交互效应。例如有三个因素变量,全模型包括三个因素变量的主效应、两两的交互效应和三个因素的交互效应。选择该项后无需进行进一步的操作,即可单击“Continue”按钮返回主对话框。此项是系统缺省项。
② Custom选项
建立自定义的分析模型。选择了“Custom”后,原被屏蔽的“Factors & Covariates”、“Model”和“Build Term(s)”栏被激活。在“Factors & Covariates”框中自动列出可以作为因素变量的变量名,其变量名后面的括号中标有字母“F”;和可以作为协变量的变量名,其变量名后面的括号中标有字母“C”。这些变量都是由用户在主对话框中定义过的。
根据表中列出的变量名建立模型,其方法如下:
在“Build Term(s)”栏右面的有一向下箭头按钮(下拉按钮),单击该按钮可以展开一小菜单,在下拉菜单中用鼠标单击某一项,下拉菜单收回,选中的交互类型占据矩形框。有如下几项选择:
Interaction 选中此项可以指定任意的交互效应; Main effects 选中此项可以指定主效应; All 2-way 指定所有2维交互效应; All 3-way 指定所有3维交互效应; All 4-way 指定所有4维交互效应 All 5-way 指定所有5维交互效应。
③ 建立分析模型中的主效应:
在“Build Term(s)”栏用下拉按钮选中主效应“Main effects”。
在变量列表栏用鼠标键单击某一个单个的因素变量名,该变量名背景将改变颜色(一般变为蓝色),单击“Build Term(s)”栏中的右拉箭头按钮,该变量出现在“Model”框中。一个变量名占一行称为主效应项。欲在模型中包括几个主效应项,就进行几次如上的操作。也可以在标有“F”变量名中标记多个变量同时送到“Model”框中。
本例将“a”和“b”变量作为主效应,按上面的方法选送到“Model”框中。
④ 建立模型中的交互项
要求在分析模型中包括哪些变量的交互效应,可以通过如下的操作建立交互项。 例如,因素变量有“a(F)”和“b(F)”,建立它们之间的相互效应。
连续在“Factors &”框的变量表中单击“a(F)”和“b(F)”变量使其选中。 单击“Build Term(s)”栏内下拉按钮,选中交互效应“Interaction”项。 单击“Build Term(s)”栏内的右拉按钮,“a*b”交互效应就出现在“Model”框
中,模型增加了一个交互效应项:a*b
⑤ Sum of squares 栏分解平方和的选择项
Type I项,分层处理平方和。仅对模型主效应之前的每项进行调整。一般适用于:
平衡的AN0VA模型,在这个模型中一阶交互
效应前指定主效应,二阶交互效应前指定一阶交互效应,依次类推;多项式回归模型。嵌套模型是指第一效应嵌套在第二
效应里,第二效应嵌套在第三效应里,嵌套的形式可使用语句指定。 Type II项,对其他所有效应进行调整。一般适用于:平衡的AN0VA模型、主因子
效应模型、回归模型、嵌套设计。
Type III项,是系统默认的处理方法。对其他任何效应均进行调整。它的优势是把
所估计剩余常量也考虑到单元频数中。对没
有缺失单元格的不平衡模型也适用,一般适用于:Type I、Type II所列的模型:没有空单元格的平衡和不平衡模型。
Type IV顶,没有缺失单元的设计使用此方法对任何效应F计算平方和。如果F不
包含在其他效应里,Type IV = Type IIIl =
TypeII。如果F包含在其他效应里,Type IV只对F的较高水平效应参数作对比。一般适用于:Type I、Type lI所列模型;
没有空单元的平衡和不平衡模型。
⑥ Include intercept in model栏选项
系统默认选项。通常截距包括在模型中。如果能假设数据通过原点,可以不包括截距,即不选择此项。
5)选择比较方法
在主对话框中单击“Contrasts”按钮,打开“Contrasts”比较设置对话框,如图5-9所示。
如图5-9 Contrasts对比设置框
在“Factors”框中显示出所有在主对话框中选中的因素变量。因素变量名后的括号中是当前的比较方法。
① 选择因子
在“Factors”框中选择想要改变比较方法的因子,即鼠标单击选中的因子。这一操作使“Change Contrast”栏中的各项被激活。
② 选择比较方法
单击“Contrast”参数框中的向下箭头,展开比较方法表。用鼠标单击选中的对照方法。可供选择的对照方法有:
None,不进行均数比较。 Deviation,除被忽略的水平外,比较预测变量或因素变量的每个水平的效应。可以
选择“Last”(最后一个水平)或
“First”(第一个水平)作为忽略的水平。
Simple,除了作为参考的水平外,对预测变量或因素变量的每一水平都与参考水平
进行比较。选择“Last”或“First”作为
参考水平。
Difference,对预测变量或因素每一水平的效应,除第一水平以外,都与其前面各
水平的平均效应进行比较。与Helmert对照
方法相反。
Helmert,对预测变量或因素的效应,除最后一个以外,都与后续的各水平的平均效
应相比较。
Repeated,对相邻的水平进行比较。对预测变量或因素的效应,除第一水平以外,
对每一水平都与它前面的水平进行比较。
Polynomial,多项式比较。第一级自由度包括线性效应与预测变量或因素水平的交
叉。第二级包括二次效应等。各水平彼此
的间隔被假设是均匀的。
③ 修改比较方法
先按步骤①选中因子变量,再选比较方法,然后单击“Change”按钮,选中的(或改变的)比较方法显示在步骤①选中的因子变量后面的括号中。
④设置比较的参考类
在“Reference Category”栏比较的参考类有两个,只有选择了“Deviation”或
“Simple”方法时才需要选择参考水平。共有两种可能的选择,最后一个水平“Last”选项和第一水平“First”项。系统默认的参考水平是“Last”。
6) 选择均值图
在主对话框中单击“Plot”按钮,打开“Profile Plots”对话框,如图5-10所示。在该对话框中设置均值轮廓图。
如图5-10 “Profile Plots”对话框
均值轮廓图(Profile Plots)用于比较边际均值。轮廓图是线图,图中每个点表明因变量在因素变量每个水平上的边际均值的估计值。如果指定了协变量,该均值则是经过协变量调整的均值。因变量做轮廓图的纵轴;一个因素变量做横轴。
做单因素方差分析时,轮廓图表明该因素各水平的因变量均值。
双因素方差分析时,指定一个因素做横轴变量,另一个因素变量的每个水平产生不同的线。如果是三因素方差分析,可以指定第三个因素变量,该因素每个水平产生一个轮廓图。双因素或多因素轮廓图中的相互平行的线表明在因素间无交互效应;不平行的线表明有交互效应。
Factors 框中为因素变量列表。 Horlzontal Axis 横坐标框,选择选择“Factors”框中一个因素变量做横坐标变
量。被选的变量名反向显示,单击向右拉箭
头按钮,将变量名送入相应的横坐标轴框中。
如果只想看该因素变量各水平的,因变量均值分布,单击“Add”按钮,将所选因素变量移入下面的“Plots”框中。否
则,不点击“Add”按钮,接着做下步。
Separate Lines 分线框。如果想看两个因素变量组合的各单元格中因变量均值分
布,或想看两个因变量间是否存在交互效应,
选择“Factors”框中另一个因素变量,单击右拉按钮将变量名送入
“Separate Lines”框中。单击“Add”按钮,将自动生成
的图形表达式送入到“Plots”栏中。分线框中的变量的每个水平将在图中是一条线。图形表达式是用“*”连接的两个因素变
量名。
Separate Plots 分图框。如果在“Factors”栏中还有因素变量,可以按上述方法,
将其送入“Separate Plot”框中,单击
“Add”按钮,将自动生成的图形表达式送入到“Plots”栏中。图形表达式是用“*’连接的三个因素变量名。分图变量的每个
水平生成一张线图。
将图形表达式送到“Plots”框后发现有错误,单击选错的变量,单击“Remove”按
钮,将其取消,再重新输入正确内容。
在检查无误后,按“Continue”按钮确认,返回到主对话框。如果取消做的设置单击“Cancel”按钮
7) 选择多重比较
在主对话框中单击“Post Hoc”选项,打开“Post Hoc Multiple Comparisons for Observed Means”对话框,从“Factor(s)”框选择变量,单击向右拉按钮,使被选变量进入“Post Hoc test for”框。本例子选择了“a”和“b”。
然后选择多重比较方法。在对话框中选择多重比较方法。本例子选择了“Duncan”和“Tamhane's T2”。
8)选择保存运算值
图5-11 Save对话框
在主对话框中,单击“Save”按钮,打开“Save”设置对话框,如图5-11所示。通过在对话框中的选择,可以将所计算的预测值、残差和检测值作为新的变量保存在编辑数据文件中。以便于在其他统计分析中使用这些值。
① Predicted Values 预测值
1. Unstsndardized,非标准化预测值。
2. Weighted,如果在主对话框中选择了WLS变量,选中该复选项,将保存加权非标准
化预测值。
3. Standard error,预测值标准误。
② Diagnostics 诊断值
1. Cook’s distance,Cook 距离。
2. Leverage values,非中心化 Leverage 值。
③ Residuals 残差
1. Unstsndardized,非标准化残差值,观测值与预测值之差。
2. Weighted,如果在主对话框中选择了WLS变量,选中该复选项,将保存加权非标准
化残差。
3. Standardized,标准化残差,又称Pearson残差。
4. Studentized,学生化残差。
5. Deleted,剔除残差,自变量值与校正预测值之差。
④ Save to New File 保存协方差矩阵
选中”Coefficient statistics”项,将参数协方差矩阵保存到一个新文件中。单击“File”按钮,打开相应的对话框将文件保存。
9)选择输出项
在主对话框中单击“Options”按钮,打开“Options”输出设置对话框,见图5-12。
图5-12 “Options”输出设置对话框
① Estimated Marginal Means 估测边际均值设置
在“Factor(s) and Factor Interactions”框中列出“Model”对话框中指定的效
应项,在该框中选定因素变量的各种效应项,
单击右拉按钮就将其复制到“Display Means for”框中。选择主效应,则产生估计的边际均值表;选择二维交互效应产生的估计
边际均值表实际上是典型的单元格均值表。选择三维交互效应也是单元格均值表。
在“Display Means for”框中有主效应时激活此框下面的“Compare main
effects”复选项,对主效应的边际均值进行组间的配
对比较。
Confidence interval adjustment参数框,进行多重组间比较。打开下拉菜单,共
有三个选项:
LSD(none)、Bonferroni、Sidak.。
② 在“Display”栏中指定要求输出的统计量
Descriptive statistics项,输出描述统计量:观测量的均值、标准差和每个单元格中的观测量数。
Estimates of effect size项,效应量估计。选择此项,给出η2(eta-Square)值。它反应了每个效应与每个参数估计值可以归于
因素的总变异的大小。
Observed power复选项,选中此项给出在假设是基于观测值时各种检验假设的功效。计算功效的显著性水平,系统默认的临界值
是0.05。
Parameter estimates项。选择此项给出了各因素变量的模型参数估计、标准误、t检验的t值、显著性概率和95%的置信区间。
Contrast coefficient matrix项,显示协方差矩阵。
Homogeneity test项,方差齐次性检验。本例子选中该项。
Spread vs.level plot项,绘制观测量均值对标准差和观测量均值对方差的图形。
Residual plot项,绘制残差图。给出观测值、预测值散点图和观测量数目,观测量数目对标准化残差的散点图,加上正态和标准化
残差的正态概率图。
Lack of fit项,检查独立变量和非独立变量间的关系是否被充分描述。
General estimable function项,可以根据一般估计函数自定义假设检验。对比系数矩阵的行与一般估计函数是线性组合的。
③ Significance level 框设置
改变“Confidence intervals”框内多重比较的显著性水平。
10) 提交执行
设置完成后,在多因素方差分析窗口框中点击“OK”按钮,SPSS就会根据设置进行运算,并将结算结果输出到SPSS结果输出窗口中。
11) 结果与分析
主要输出结果:
结果分析:
方差不齐次性检验显著
表5-8 方差齐次性检验表明:方差不齐次性显著,p
方差分析:
表5-9 主效应方差分析表:在表的左上方标明研究的对象是粘虫历期。
偏差来源和偏差平方和:
Source 列是偏差的来源。其次列是“Type III Sum of Squares”偏差平方和。
Corrected Model 校正模型,其偏差平方和等于两个主效应a、b平方和加上交互
a*b的平方和之和。
Intercept 截距。 a 温度主效应,其偏差平方和反应的是不同温度造成对粘虫历期的差异。与b偏差
平方相同均属于组间偏差平方和。
b 湿度主效应,其偏差平方和反应的是不同湿度计量造成的粘虫历期之差异。 a*b 温度和湿度交互效应,其偏差平方和反应的是不同温度和湿度共同造成的粘虫
历期的差异。
Error 误差。其偏差平方和反应的是组内差异。也称组内偏差平方和。 Total 是偏差平方和在数值上等于截距、主效应、次效应和误差偏差平方和之总和。 Corrected Total 校正总和。其偏差平方和等于校正模型与误差之偏差平方和之总
和。
df 自由度 Mean Square 均方,数值上等于偏差平方和除以相应的自由度。 F 值,是各效应项与误差项的均方之比值 Sig 进行F检验的p值。p≤0.05,由此得出“温度”和“湿度”对因变量“粘虫历
期”在0.05水平上是有显著性差异的。
根据方差分析表明:
不同温度(a)对粘虫历期的偏差均方是1575.434,F值为90.882,显著性水平是
0.000,即p
不同湿度(b)对粘虫历期的偏差均方是322.000,F值为18.575,显著性水平是0.000,
即p
不同温度和不同湿度(a*b)共同对粘虫历期的偏差均方是19.809,F值为1.143,
显著性水平是0.358,即p>0.05存在不显著性
差异。
多重比较
由于方差不齐次性,应选择方差不具有齐次性时的“Tamhane's T2”t检验进行配对比较。表5-10 多重比较表就是“温度”各水平“Tamhane's T2”方法比较的结果。表中的各项说明参见表5-6(5.2.2节)。
温度25℃与27℃、29℃和31℃之间都有显著性差异; 温度27℃与25℃、29℃和31℃之间都有显著性差异; 温度29℃与26℃和27℃之间都有显著性差异;与31℃无显著性差异; 温度31℃与25℃和27℃之间都有显著性差异;与29℃无显著性差异。
不同湿度水平之间无显著性差异存在,这里没有列出多重比较表。
百度搜索“爱华网”,专业资料,生活学习,尽在爱华网