决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。决策树是数据挖掘分类算法的一个重要方法。在各种分类算法中,决策树是最直观的一种。
决策树分析法_决策树 -原理
决策树
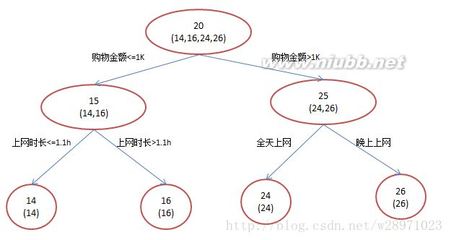
决策树提供了一种展示类似在什么条件下会得到什么值这类规则的方法。比如,在贷款申请中,要对申请的风险大小做出判断,图是为了解决这个问题而建立的一棵决策树,从中我们可以看到决策树的基本组成部分:决策节点、分支和叶子。决策树中最上面的节点称为根节点,是整个决策树的开始。
本例中根节点是“收入>¥40,000”,对此问题的不同回答产生了“是”和“否”两个分支。决策树的每个节点子节点的个数与决策树在用的算法有关。如CART算法得到的决策树每个节点有两个分支,这种树称为二叉树。允许节点含有多于两个子节点的树称为多叉树。决策树的内部节点(非树叶节点)表示在一个属性上的测试。每个分支要么是一个新的决策节点,要么是树的结尾,称为叶子。在沿着决策树从上到下遍历的过程中,在每个节点都会遇到一个问题,对每个节点上问题的不同回答导致不同的分支,最后会到达一个叶子节点。这个过程就是利用决策树进行分类的过程,利用几个变量(每个变量对应一个问题)来判断所属的类别(最后每个叶子会对应一个类别)。决策树分析法_决策树 -应用
假如负责借贷的银行官员利用上面这棵决策树来决定支持哪些贷款和拒绝哪些贷款,那么他就可以用贷款申请表来运行这棵决策树,用决策树来判断风险的大小。“年收入>¥40,00”和“高负债”的用户被认为是“高风险”,同时“收入<¥40,000”但“工作时间>5年”的申请,则被认为“低风险”而建议贷款给他/她。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测(就像上面的银行官员用他来预测贷款风险)。常用的算法有CHAID、CART、Quest和C5.0。建立决策树的过程,即树的生长过程是不断的把数据进行切分的过程,每次切分对应一个问题,也对应着一个节点。对每个切分都要求分成的组之间的“差异”最大。决策树分析法_决策树 -区别
各种决策树算法之间的主要区别就是对这个“差异”衡量方式的区别。对具体衡量方式算法的讨论超出了本文的范围,在此我们只需要把切分看成是把一组数据分成几份,份与份之间尽量不同,而同一份内的数据尽量相同。这个切分的过程也可称为数据的“纯化”。看我们的例子,包含两个类别--低风险和高风险。如果经过一次切分后得到的分组,每个分组中的数据都属于同一个类别,显然达到这样效果的切分方法就是我们所追求的。到现在为止我们所讨论的例子都是非常简单的,树也容易理解,当然实际中应用的决策树可能非常复杂。假定我们利用历史数据建立了一个包含几百个属性、输出的类有十几种的决策树,这样的一棵树对人来说可能太复杂了,但每一条从根结点到叶子节点的路径所描述的含义仍然是可以理解的。决策树的这种易理解性对数据挖掘的使用者来说是一个显著的优点。决策树分析法_决策树 -缺点
然而决策树的这种明确性可能带来误导。比如,决策树每个节点对应分割的定义都是非常明确毫不含糊的,但在实际生活中这种明确可能带来麻烦(凭什么说年收入¥40,001的人具有较小的信用风险而¥40,000的人就没有)。建立一颗决策树可能只要对数据库进行几遍扫描之后就能完成,这也意味着需要的计算资源较少,而且可以很容易的处理包含很多预测变量的情况,因此决策树模型可以建立得很快,并适合应用到大量的数据上。对最终要拿给人看的决策树来说,在建立过程中让其生长的太“枝繁叶茂”是没有必要的,这样既降低了树的可理解性和可用性,同时也使决策树本身对历史数据的依赖性增大,也就是说这是这棵决策树对此历史数据可能非常准确,一旦应用到新的数据时准确性却急剧下降,我们称这种情况为训练过度。为了使得到的决策树所蕴含的规则具有普遍意义,必须防止训练过度,同时也减少了训练的时间。因此我们需要有一种方法能让我们在适当的时候停止树的生长。常用的方法是设定决策树的最大高度(层数)来限制树的生长。还有一种方法是设定每个节点必须包含的最少记录数,当节点中记录的个数小于这个数值时就停止分割。与设置停止增长条件相对应的是在树建立好之后对其进行修剪。先允许树尽量生长,然后再把树修剪到较小的尺寸,当然在修剪的同时要求尽量保持决策树的准确度尽量不要下降太多。决策树分析法_决策树 -评论
对决策树常见的批评是说其在为一个节点选择怎样进行分割时使用“贪心”算法。此种算法在决定当前这个分割时根本不考虑此次选择会对将来的分割造成什么样的影响。换句话说,所有的分割都是顺序完成的,一个节点完成分割之后不可能以后再有机会回过头来再考察此次分割的合理性,每次分割都是依赖于他前面的分割方法,也就是说决策树中所有的分割都受根结点的第一次分割的影响,只要第一次分割有一点点不同,那么由此得到的整个决策树就会完全不同。那么是否在选择一个节点的分割的同时向后考虑两层甚至更多的方法,会具有更好的结果呢?目前我们知道的还不是很清楚,但至少这种方法使建立决策树的计算量成倍的增长,因此现在还没有哪个产品使用这种方法。而且,通常的分割算法在决定怎么在一个节点进行分割时,都只考察一个预测变量,即节点用于分割的问题只与一个变量有关。这样生成的决策树在有些本应很明确的情况下可能变得复杂而且意义含混,为此目前新提出的一些算法开始在一个节点同时用多个变量来决定分割的方法。比如以前的决策树中可能只能出现类似“收入<¥35,000”的判断,现在则可以用“收入<(0.35*抵押)”或“收入>¥35,000或抵押<150,000”这样的问题。
决策树分析法_决策树 -优势
决策树很擅长处理非数值型数据,这与神经网络只能处理数值型数据比起来,就免去了很多数据预处理工作。甚至有些决策树算法专为处理非数值型数据而设计,因此当采用此种方法建立决策树同时又要处理数值型数据时,反而要做把数值型数据映射到非数值型数据的预处理。决策树分析法_决策树 -分析法
决策树分析法是通过决策树图形展示临床重要结局,明确思路,比较各种备选方案预期结果进行决策的方法。决策树分析法通常有6个步骤。
第一步:明确决策问题,确定备选方案。对要解决的问题应该有清楚的界定,应该列出所有可能的备选方案。
第二步:绘出决策树图形。决策树用3种不同的符号分别表示决策结、机会结、结局结。决策结用图形符号如方框表示,放在决策树的左端,每个备选方案用从该结引出的]个臂(线条)表示;实施每一个备选方案时都司能发生一系列受机遇控制的机会事件,用图形符号圆圈表示,称为机会结,每一个机会结司以有多个直接结局,例如某种治疗方案有3个结局(治愈、改善、药物毒性致死),则机会结有3个臂。最终结局用图形符号如小三角形表示,称为结局结,总是放在决策树最右端。从左至右机会结的顺序应该依照事件的时间先后关系而定。但不管机会结有多少个结局,从每个机会结引出的结局必须是互相排斥的状态,不能互相包容或交叉。
第三步:明确各种结局可能出现的概率。可以从文献中类似的病人去查找相关的概率,也可以从临床经验进行推测。所有这些概率都要在决策树上标示出来。在为每一个机会结发出的直接结局臂标记发生概率时,必须注意各概率相加之和必须为1.0。
第四步:对最终结局用适宜的效用值赋值。效用值是病人对健康状态偏好程度的测量,通常应用0-1的数字表示,一般最好的健康状态为1,死亡为0。有时可以用寿命年、质量调整寿命年表示。
第五步:计算每一种备远方案的期望值。计算期望值的方法是从"树尖"开始向"树根"的方向进行计算,将每一个机会结所有的结局效用值与其发生概率分别相乘,其总和为该机会结的期望效用值。在每一个决策臂中,各机会结的期望效用值分别与其发生概率相乘,其总和为该决策方案的期望效用值,选择期望值最高的备选方案为决策方案。
第六步:应用敏感性试验对决策分析的结论进行测试。敏感分析的目的是测试决策分析结论的真实性。敏感分析要回答的问题是当概率及结局效用值等在一个合理的范围内变动时,决策分析的结论会不会改变。
决策树分析法_决策树 -画法
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。从数据产生决策树的机器学习技术叫做决策树学习,通俗说就是决策树。
一个决策树包含三种类型的节点:
决策节点:通常用矩形框来表式
机会节点:通常用圆圈来表式
终结点:通常用三角形来表示
决策树学习也是资料探勘中一个普通的方法。在这里,每个决策树都表述了一种树型结构,它由它的分支来对该类型的对象依靠属性进行分类。每个决策树可以依靠对源数据库的分割进行数据测试。这个过程可以递归式的对树进行修剪。当不能再进行分割或一个单独的类可以被应用于某一分支时,递归过程就完成了。另外,随机森林分类器将许多决策树结合起来以提升分类的正确率。
决策树同时也可以依靠计算条件概率来构造。
决策树如果依靠数学的计算方法可以取得更加理想的效果。数据库已如下所示:
(x,y)=(x1,x2,x3…,xk,y)
相关的变量Y表示我们尝试去理解,分类或者更一般化的结果。其他的变量x1,x2,x3等则是帮助我们达到目的的变量。
决策树分析法_决策树 -实例
为了适应市场的需要,某地准备扩大电视机生产。市场预测表明:产品销路好的概率为0.7;销路差的概率为0.3。备选方案有三个:第一个方案是建设大工厂,需要投资600万元,可使用10年;如销路好,每年可赢利200万元;如销路不好,每年会亏损40万元。第二个方案是建设小工厂,需投资280万元;如销路好,每年可赢利80万元;如销路不好,每年也会赢利60万元。第三个方案也是先建设小工厂,但是如销路好,3年后扩建,扩建需投资400万元,可使用7年,扩建后每年会赢利190万元。各点期望:
点②:0.7×200×10+0.3×(-40)×10-600(投资)=680(万元)
决策树分析
点⑤:1.0×190×7-400=930(万元)
点⑥:1.0×80×7=560(万元)
比较决策点4的情况可以看到,由于点⑤(930万元)与点⑥(560万元)相比,点⑤的期望利润值较大,因此应采用扩建的方案,而舍弃不扩建的方案。把点⑤的930万元移到点4来,可计算出点③的期望利润值。
点③:0.7×80×3+0.7×930+0.3×60×(3+7)-280 = 719(万元)
最后比较决策点1的情况。由于点③(719万元)与点②(680万元)相比,点③的期望利润值较大,因此取点③而舍点②。这样,相比之下,建设大工厂的方案不是最优方案,合理的策略应采用前3年建小工厂,如销路好,后7年进行扩建的方案。