摘要: 企业质量数据的激增使手工进行质量数据的处理和分析越来越困难,为解决这一问题,本文将在简要介绍SPSS统计软件的基础上,通过示例介绍了SPSS在质量数据的收集、统计描述、控制图绘制、正交实验结果分析和样本信息的参数检验等方面的应用,以期对质量工作者有所帮助。
关键词:质量数据 SPSS 控制图 正交实验 参数检验
目前,企业的各种质量数据量越来越大,对质量数据的处理工作量就异常巨大,软件研究人员把它们称作海量数据。海量数据有以下两个特点:首先,数据量庞大,由于企业规模扩张、产品品种急剧增加、产品产量的增大,其质量特征信息量也必然十分庞大。其次,海量数据集的隐性特征和特征数据的获得十分困难,数据的隐性特征是指数据的相关特性,特征数据包括样本的对称性、中心位置、分布特征等。由于企业间竞争的日益激烈,企业管理者对质量信息的要求也越来越高,对这些信息处理要求的时间也越来越短;但是,管理者要想海量数据中提炼出想要得到的分析结果,如果只是简单的利用人力进行统计、计算、分析的话,那必将错过控制质量的最好机会;而且,很有可能因为工作量太大,而引起最后结果的误差增大或发生计算过程的错误,从而使最后的结果不能反映现实情况,这些都将对企业产生较大的损失。因此,企业要进行科学的质量管理客观上需要专业性的统计分析软件作为工具。
1.SPSS统计软件简介
随着计算机技术的发展,数据统计功能也开始在计算机中得到应用。最初,从20世纪60年代起大约持续到1980年前后,期间的计算机统计软件主要应用在大型数据集的计算和建议分析模型(如回归分析)的创建,当时研究的前沿统计技术主要集中在多元数据分析模型的尝试性创建和数据的再分析,比如因子分析、判别分析、时间序列分析等。SPSS是现代统计软件的典型代表,其全称是:Statistical Program for Social Sciences,即社会科学统计程序,该软件是公认的最优秀的统计分析软件包之一。SPSS原是为大型计算机开发的,其版本为SPSSx;80年代初,微机开始普及以后又推出了微机版本(版本为SPSS/PC+ x.x),迅速扩大了用户量;80年代末,Microsoft发布Windows后,SPSS迅速向Windows移植。至1993年6月,正式推出SPSS for Windows 6.0版本。该版本不仅修正了以前版本的错误,改写一些模块使运行速度大大提高。而且根据统计理论与技术的发展,增加了许多新的统计分析方法,使之功能日臻完善。目前SPSS的最新版本为SPSS for Windows 12。与以往的SPSS for DOS版本相比,SPSS for Windows显得更加直观易用。首先,它采用现今广为流行的电子表格形式作数据管理器,使用户变量命名、定义数据格式、数据输入与修改等过程一气呵成,免除了原DOS版本在文本方式下数据录入的诸多不便;其次,采用菜单方式选择统计分析命令,采用对话框方式选择子命令,简明快捷,无需死记大量繁冗的语法语句,这无疑是计算机操作的一次解放;第三,采用对象连接和嵌入技术,使计算结果可方便地被其他软件调用,数据共享,提高工作效率[1]。
我国目前正在使用的用户中,绝大部分是使用9.0~11.5版本[2]。
作为统计分析工具,SPSS的功能包括数据统计管理、统计分析、趋势研究、制表绘图、文字处理等。SPSS对质量信息的管理,是指在生产、管理的所有阶段借助SPSS统计软件、运用统计方法对产品质量信息、数据所进行的处理和分析过程。其具体操作主要包括:数据的收集和简单处理、编制统计质量控制图、线外质量控制(又称试验设计)、抽样验收等[3]。2. 质量数据的收集与简单管理
统计数据是指经过收集、整理和概括后用来表达和说明事物特征或属性的概念和数值。统计数据是集合性的,是根据某一项特定的研究特征归纳在一起的。把同类型的数据合在一起,形成一个集合,就构成了数据集。数据集是统计数据的简单集合,一般具有大量性、差异性和同质性三个特征。数据集市统计软件研究的基本单元,是统计分析的起点。创建一个稳健、有效率的数据集对于正确的统计分析十分重要。质量信息数据集就是SPSS针对各类质量信息、数据所建立的数据集合,SPSS利用质量信息数据集对其进行统计分析。质量信息数据的收集在这里是指将生产、检验等过程中所得到的质量数据在SPSS软件中建立质量数据集;对于获得的不是数据性的信息,要进行数据化处理,转化为可以统计分析的数据,进而建立数据集。对于所建立数据集的简单管理包括数据、单元格的查找,观测量的分类排序,数据文件的分类汇总和数据的选择等。质量信息数据集如何建以及数据集的简单管理,其操作步骤与一般数据的SPSS数据集的建立相同,可查阅专门的SPSS软件教材。
3. 质量数据的统计描述
要对质量数据做好统计分析,首先要对这些数据进行描述性统计分析。SPSS统计软件对质量信息的描述统计分析功能主要集中在Descriptive Statistics菜单中,主要包括建立质量数据频率表,质量数据的一般性统计描述、探索性分析和交叉统计等,下面对质量信息应用较多的数据频率表和一般性统计描述进行举例讲述。3.1 建立质量数据频率表
SPSS统计软件建立数据频率表由“Analyze”菜单中“Descriptive Statistics”的“Frequencies…”项来完成。例如,图1所示数据集是对某地区的五类产品的质量顾客满意度调查后,对调查者所从业岗位信息的统计数据集。其中,变量“产品类”的变量值“1”、“2”、“3”、“4”、“5”分别表示家电类、轻工类、食品类、纺织品和生产资料类产品;变量“调查者”的变量值“1”、“2”、“3”、“4”、“5”分别表示机关或事业单位、企业、军人、农民和其他,这些信息的数据化均在定义变量时的标签中注明。具体操作如下:图1 “产品类—调查者”数据集打开“Analyze”菜单,选择“Descriptive Statistics”中的“Frequencies…”项,弹出“Frequencies”对话框,将两个变量选入“Variable(s)”框内。单击“Statistics”按钮。可以弹出“Frequencies:Statistics”对话框,其中,Percentile Values“复选框组定义了需要输出的百分位数;“Central tendency”复选框组主要用来定义描述集中趋势的一组指标:均值(Mean)、中位数(Median)、众数(Mode)、总合(Sum);“Dispersion”复选框组用于定义标准差(Std.deviation)、方差(Variance)、全距(Range)等描述离散趋势的一组指标;“Distribution”复选框组用于定义描述分布特征的两个指标:偏度系数(Skewness)和峰度系数(Kurtosis)。点击“Statistics”对话框中的“Charts”按钮可以选择是否在输出结果中输出所要求的辅助图形,例如条形图、直方图等,本例选择饼图(Pie chart)。点击“Statistics”对话框中的“Format”按钮可以定义输出频数表的格式。最后,点击“OK”,可以得到如表1的频率表和图2的频率饼图。
3.2 质量数据的一般性统计描述
质量数据的一般性统计描述主要是指对连续性随机变量进行的一般描述统计。这个过程及可以对变量进行描述性统计分析,列出一系列相应的统计指标,还可以将原始数据转换成标准正态评分值并以变量的形式存入数据库以供分析。这一功能是由SPSS的“Analyze”菜单中“Descriptive Statistics”的“Descriptive…”项来完成。例如,某一企业要统计每个车间(共两个)在一个月内所付出的质量成本,并统计预防成本、鉴定成本、内部损失成本和外部损失成本的差异,由所统计数据建立SPSS数据文件如表2所示。要求对这些数据进行一般性统计描述,得到各项所需指标,操作如下:打开“Analyze”菜单选中“Descriptive Statistics”中的“Descriptions…”项,则会弹出“Descriptives”对话框。将六个变量均选入“Variable(s):”框内,如果选中“Save standardized values as variables”复选框,则将六个变量的原始数据的标准正态评分存为新变量,列在后面(此例不选)。如果,点击“Descriptives”对话框中的“Options…”按钮,则会弹出“Descriptions Options”对话框,在其中可以设置如图3中的各项所需的统计指标。统计结果如表3所示。
4. 绘制质量控制图
SPSS的图形工具非常强大,具有很强的统计分析功能。在质量数据管理中,经常要用到一些图形方法和工具,例如帕雷托图、直方图、散点图、控制图、序列图等,SPSS均可以有效的应用这些图形方法和工具来处理质量数据信息,这些功能集中在Graph菜单中。控制图可以帮助人们区分所寻找的与过程有关的质量问题是系统原因造成的还是偶然因素造成的,因此,控制图在质量管理中有着广泛地的应用。下面以实例介绍SPSS软件如何绘制质量控制图。
例:某化学用品厂生产一种产品,每件产品需要反应试剂至少为1克,但是不能超过50克。为了控制生产过程,准备用控制图对生产过程进行监控,步骤如下:
第一步:建立数据文件。经确定,本例应用平均值—极差控制图,每5个观测值作为一组,如图4所示。
第二步:点击Graph菜单中的“control”项,弹出“Control Charts”对话框。其中“X-Bar,R,s”表示均值、极差、标准差控制图;“Inpiduals Moving”表示单值、移动极差控制图;“p,np”表示不合格率、不合格数控制图;“c,u”表示缺陷数、单位缺陷数控制图。在此,选择“X-Bar,R,s”。并选择数据组织方式为“Cases are units”表示观测量分类模式。
第三步:单击“Define”按钮,将弹出“X-Bar,R,s:Cases Are Units”对话框,其中,“Process Measurement”框用于选择工序变量,也就是待分析变量;“Subgroups Defined by”用于选择分组变量;“X-Bar and range”表示绘制平均值—极差控制图;“X-Bar and standard deviation”表示要绘制均值—标准差控制图。在此将变量“重量”选入“Process Measurement”;将变量“组号”选入“Subgroups Defined by”;选择“X-Bar and range”,即平均值—极差控制图。
第四步:单击“Options”按钮,打开“X-Bar,R,s:Options”对话框,其中,“Number of Sigmas”表示用于选择上、下控制线的距离为标准差的多少倍,在此填入“3”; “Minimum subgroup size”为每组的最小样本容量,在此填入“5”;“Display subgroups defined by missing values”表示显示缺失值的组,在此不选择,点击“Continue”。“Statistics…”对话框中“Specification Limits”框用于设置上、下参考线,用以比较数据,在此可以分别填入“45”和“25”。
最后,点击“OK”,即可以绘出所要求的控制图,结果如图5和图6所示。
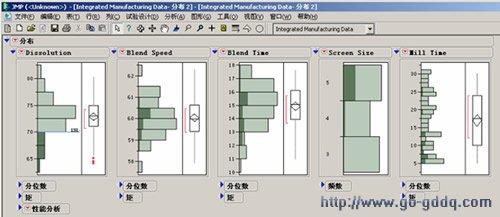
通过此控制图就可以看到均值、极差上下控制线以及平均值,还可以看到在25和45参考线以外的组号,并且通过分析,可以知道两张控制图无任何异常,说明生产过程是正常的,是受控的。
5. 质量管理的设计实验
正交实验设计在提高产品质量水平、新工艺的开发和优化等过程中有重要的应用。本文用一个实例介绍SPSS统计软件对正交实验设计的数据分析过程。某轴承厂生产的轴承内套圈硬度不均匀,热处理淬火QC小组决定通过正交实验来优选淬火工艺参数,提高内套圈硬度均匀的合格率。经过分析,确定“淬火加热温度”、“淬火加热保温时间”、“回火加热温度”和“回火保温时间”为造成硬度不均匀的主要原因。根据以往经验,对四个因素各取三个水平:淬火加热温度分别为:835、845、855摄氏度;淬火加热保温时间分别为:20、15、10分钟;回火温度为:160、170、180摄氏度;回火保温时间为:2、2.5、3小时。
第一步,建立spss的数据集文件如图7。第二步,分析过程如下:
①单击Analyze菜单,选择General Linear Models项。从中打开多因子方差分析“Univariate”对话框,见图8。将变量“合格率”选入“Dependent Variable”框,将其它变量选入“Fixed Factor(s)”。②点击“Options…”按钮,打开“Univariate:Options”对话框,将四个变量分别依次选入“Display means for”框内,点击“continue”。③点击“Model…”按钮,打开“Univariate:Model”对话框,选择“custom”,将四个变量分别依次选入“Model”框内,点击“continue”。④点击“OK”,统计分析结果如图12、13、14所示。由结果中的“Test of Between_Subjects Effects”表可以知道,在α=0.05的显著性水平下,“淬火加热温度”和“回火保温时间”对实验结果的影响是显著的,可以优先采用它们的最好水平。适当的考虑多方面的因素,我们就可以得到一个最佳的工作方式组合。由表4的“Estimated Marginal Means”单因素统计量表中“Type III Sum of squares”列的数据可以看出:淬火加热温度是最重要的因素,其次依次分别是回火保温、淬火保温和回火温度;通过对表5中“Mean”列的数据比较,可知我们应该选择每个因素的最佳水平分别为:淬火加热温度选择水平3,即855摄氏度;回火保温时间选择水平1,即2小时;淬火加热保温时间选择水平1,即20分钟;回火温度选择水平2,即170摄氏度。另外,点击“Univariate”中对话框其它按钮以及在“Univariate:Options”对话框和“Univariate:Model”对话框内,均可以设置更多统计分析要求。
6.样本信息的参数检验
在实际的生产、检验过程中,并不是对全部产品的特性进行测量,而是借助对所选择样本产品特性的测量,对样本所在的整体进行假设检验,以确定整批产品的合格与否,从而做出决策。SPSS软件的参数检验,主要是要通过相伴概率值与显著性水平的比较,来决定拒绝还是接受原假设。在此,我们以最常用的t检验来说明SPSS在参数检验中的应用。t检验可以分为单样本t检验、两独立样本t检验和配对样本t检验。下面将以单样本t检验为例简单介绍SPSS在参数检验中的用法,两独立样本t检验和配对样本t检验分别由“Analyze”菜单中“compare means”的“Independent-Samples T Test”项和“Paired-Samples T Test”项来完成,操作与单样本t检验类同,在此不进行详细叙述。
例:某电器厂生产一种云母片,要求厚度均值为13mm,今在某天生产的云母片中随机抽取26片,分别测量其厚度为(mm):12、14.5、14、13.7、14.2、12.9、13.5、12.8、14.4、15、13.7、13.1、12.9、14、13.8、14.2、13.6、15.0、13.5、12.7、14.1、15.2、13.6、12.8、14.3、13.4。现在我们检验今天生产的云母片厚度均值是否与规定的质量分布要求有无显著差异(α=0.05)。
第一步,建立SPSS的数据文件。
第二步,单击“Analyze”菜单中“compare means”的“One Samples T Test”项,打开“One-Sample T Test”对话框,见图9。将变量“厚度”选入“Test variable(s)”框内,表示需要对之进行分析;在“Test value:”中填入总体均值13,点击“OK”。第三步,点击“Options”按钮,打开“One-Sample T Test:Options”对话框,见图10。在“Confidence Interval”内输入95,表示置信区间为95%;“Missing Values”是对缺省值的处理,在此选择“Exclude cases analysis by analysis”,表示具体分析用到的变量有缺失值才除去该记录,点击“Continue”按钮。最后,点击“OK”,结果如表6所示。由结果中的“One-Sample Statistics”表可以知道样本数为26,样本均值为13.73mm,标准差为0.78,均值标准误差为0.15。由结果中的“One-Sample Test”表可以知道t统计量的值为4.739,由于差值95%的置信区间(0.4110,1.0428)没有包括4.739,表示这个差值落在了区间之外,因此可以断定,今天生产的云母片厚度不符合质量分布要求。
7.小结
通过对SPSS在质量信息管理中的应用进行了初步探讨,不难发现尽管SPSS是一种通用的社会科学统计软件,但非常适用于质量数据的处理和分析,广大质量工作者可以逐步探索SPSS在质量管理中的新用途,大幅度改善质量管理的效率和效果,帮助管理者做出最优决策,最大限度地提高产品和服务质量。参考文献[1]卢纹岱 主编. SPSS for Windows统计分析[M]. 北京:电子工业出版社,2000.6: 2~4[2]黄海, 罗友丰, 陈志英 主编. SPSS 10.0 for Windows 统计分析[M]. 北京:人民邮电出版社, 2001.2: 5~7 [3]范正绮. 西方统计质量管理的操作手段[J]. 外国经济与管理,1996(5): 47~48作者简介:李开鹏(1980-),男,山东大学管理学院硕士研究生。