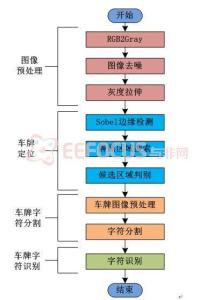
车牌识别系统 是计算机视频图像识别技术在车辆牌照识别中的一种应用。以下是爱华网小编为大家整理的关于车牌定位流程图,给大家作为参考,欢迎阅读!
车牌定位流程图 车牌定位方法1. 预处理
由于光线不足或者反光等诸多因素,有可能造成车牌对比度较差,对接下来的纹理分析产生影响,所以有必要进行图象增强。图象拉伸是增加图象对比度的一个好方法,但简单的图象拉伸有可能造成拉伸过度,损失了车牌区域的细节。
本文提出的方法是根据原图象对比度采用自适应拉伸的方法,经实验证明能有效增强图象对比度,提高了车牌定位准确率。
灰度拉伸公式如下:
p1和p2根据动态范围p做自适应调整。我们使用的参数是:p>0.8时,p1=p2=0.2;p>0.5时,p1=p2=0.15;其余p1=p2=0;在实验中收到了良好的效果。图1是原图象,图2是用本文的自适应拉伸法处理后的图象,可以看到图2的对比度增强了,牌照字符的边缘更加清晰,有利于后面的定位处理。
2. 车牌定位
当我们从远处观察车辆时,判别牌照区域的主要依据是车牌的颜色、亮度和车牌字符的边缘形成的纹理。所以,充分利用这些信息就成了定位车牌的关键。
2.1 粗定位
牌照区域区别于其他区域的地方就在于牌照上有字符,这一特征体现在图象的灰度上就是其水平投影具有较好的连续性,不会有大的起伏,体现在纹理信息上就是其垂直边缘的间距较有规律。本文的车牌定位方法就是基于这两个特征的结合进行的,从而更有效地排除干扰区域,更快速地进行车牌的定位。
1) 水平定位
首先,我们要找出车牌所在的水平位置。虽然车牌区域内水平方向有着较大的灰度变化,但由于字符在竖直方向上的灰度有着较好的连续性,在车牌范围内的水平灰度投影不会有很大的起伏,而在车牌之外的上下区域由于车身或背景的关系投影值则明显不同。
同时车牌区域除了在水平方向应有的灰度连续性,还应该具有一定灰度变化频度。为了统计灰度变化频度,经试验比较,在我们的算法中采用简单快速的水平梯度算子[-1 1]。通过二值化水平梯度图提取具有最大梯度的边缘,同时去除了大多数噪声的干扰。因为成像模糊等原因使提取的有些边缘宽度大1,我们对边缘图象再一次做水平差分计算。经运算后边缘图象轮廓清晰,车辆牌照子图象区域完全凸现出来,而车体上其他部分和背景中的轮廓线特征往往并不突出。
由于搜索整幅位图,速度非常慢,为了缩小搜索范围,加快定位速度,算法采用如下方法:
(1) 每间隔10行扫描一行,记下变化频度最大的行号i 。
(2) 从中选出最大的10行,R{row (i) | i = 0,1,…,9}。记row(i) 的灰度投影值为pro (row(i)),记投影变化的下门限为th_low,上门限为th_high,记水平方向灰度变化频度的门限是th_edge。
(3) 对R中每一个row (i)向上或向下扫描灰度投影,以{th_low *pro(row(i)), th_high *pro(row(i))}向上和向下做区域增长,同时考虑变化频度是否满足要求。实际由于各种原因,有时不是车牌范围内的每一行都满足灰度投影连续性和变化频度的要求,所以我们允许对不满足要求的连续的行数和总行数有一定的冗余。
(4) 对得到的高度区域进行筛选,去掉高度不合格的区域。筛选到的区域送到下一步确定左右边界。
在实验中,一般只有1--3个有效的候选区域,减少搜索量为原来的1/2以上,但准确率却提高了50%以上,收到了很好的实效。投影和变化频度在搜索中有效的结合不仅提高了水平定位的准确性,而且使得算法对区域增长的阈值不敏感,提高了系统的鲁棒性。
图3中的水平长直线是用此方法得到的车牌候选区的水平位置,这三个水平位置正是图象中包含字符串的类车牌区的所在。经实验证明,此方法对确定车牌的水平位置十分有效,在我们所试验的200多张图象中,全部找到了车牌所在的水平位置。
2) 垂直定位
接着,我们对经水平定位得到的每个区域分别进行垂直定位。我们发现,不是所有的车牌都有边框,并且当车牌底色和车身颜色相近时车牌的边界也不存在了。所以,如果车牌有边框或边界,可以以此来定位;如果没有,可以对最左边和最右边的字符的边缘定位。为了提高边缘的抗干扰能力,我们采用动态阈值的Canny算子,上阈值用式(7)计算,下阈值为上阈值的0.7倍。由于搜索Canny边缘是在水平定位子图像上进行,所以速度很快,不影响整个系统的实时性。从图4可以看到用此方法提取的边缘什分清晰准确。
式(7)中c(i) 为水平定位子图像的灰度累积直方图。
那么怎么得到车牌的左右边界呢?进一步分析车牌纹理特征,除了在水平方向有一定的边缘外,这些边缘还应该是集中地分布在一定范围内,间隔较有规律。因此,方法如下:
扫描每个水平定位子图像的每一行l (i, j) ,( i=1……q, j=1……h (i) )。q为子图像数,h (i)为第i 个子图像的高度。设子图像i 的扫描起始列为c。
(1) 从行l (i, j)的扫描起始列c开始扫描,将c后的第一个边缘点记为这一行的起始点,即第一个有效点。
(2) 如果下一个边缘点和上一个有效点的距离小于1.3×h (i),则这一点为有效点,否则为无效点。如果一行的连续无效点和无效点总数大于冗余阈值,这一行为无效行,继续下一行扫描。如果一行的有效点数大于灰度变化频度th_edge,这一行为有效行,并将最后一个有效点暂时作为行结束点。
(3) 如果行结束点后仍有有效点,则行结束点为依次为最后一个有效点。
(4) 如果一个水平子图像没有有效行,则这个子图像为无效区域;否则为有效区域,记录有效行的起始点和结束点来计算车牌的左右边界。计算方法在后面介绍。
(5) 如果有效区域的右边界小于图象宽度,则可能还有其他有效区域,记c=右边界+1,返回 (1)继续扫描。
得到了一个区域的若干行的起始点和结束点,接下来判定这个有效区域的左右边界。如果将此看作一个直线拟和问题,可以采用最小平方误差法:
式(8)中t 为待估计的左边界或右边界,xi 为起始点或结束点。这个方法的优点是计算简单,但如果有几个噪声点干扰的话,拟和结果明显变差,定位不准确。为了解决这个问题,我们采用以下的方程:
式(9)与式(8)不同,其值越大则拟和的位置越正确。这个方程的最重要的特点是:一个点离拟和的位置越远,它对方程所做的贡献越小,因此少数的噪声点不会影响拟和的结果,具有很好的抗噪声能力。所以,定位左右边界的过程就是一个在小范围内找拟和最大值的过程。
从图3可以看到,我们的方法十分有效,图中的4个含有字符串的类牌照区都被准确地找到了左右边界。再看图4,车牌的左边界位置是最左边的字符"B"的左边缘,右边界位置是车牌的右边缘,符合我们的预期。
2.2 精确定位
大多数情况下,车牌已被准确定位了,但车牌字符上面和下面的铆钉有时使水平定位过大,这会影响后面的字符分割。另外我们将台湾省的车牌类型也考虑在内,从图(6)中可以看到这种车牌为双行结构,上行为中文小字,一般写着"台湾省",位置处于两个铆钉的中间。由于其字体很小无法做识别且信息量不大,所以应在精确定位时把它们和其他干扰区一齐去除。
从图(6)中可以看到,车牌下行字符和上行字符的中间是一个空白带,基本没有什么边缘。用阈值来分割这种边缘变化不具有很强的鲁棒性,容易受到噪声的干扰。将水平定位时获得边缘做水平投影,可以发现在铆钉与车牌字符的中间具有较小的投影值。二次差分比率函数具有检测波峰、波谷的能力,因此计算边缘投影的二次差分比率如下:
式(10)中v(i)为水平边缘投影,f(i)为二次方差比率值。这个函数的特点是值越小,邻域的变化越大,函数值就越大,因此具有检测波谷的能力。为了减少噪声和车牌倾斜的影响,我们设计了一个累积加权的方法,具体如下:
(1) 我们将投影值为0,1,2的行都视为波谷,权值分别为w_0,w_1,w_2,其余的权值为1;
(2) 权值从第一行开始累加,如果是权值是1,则不累加,保持为1。因此波谷越宽,累积的权值将越大。
(3) 将累加得到的权值乘和对应行的二次差分比率值相乘。
这样,波谷的二次差分比率值得到了增强,最大值所对应的行就是我们所要的分割位置。
图 5 式(10) 图 6 初定位后的车牌 图7 精确定位后的车牌
的累积加权值
图(6)是粗定位后得到的结果的二值图。用上述方法计算图(6)的边缘水平投影的加权二次差分比率,得到图(5)。从图(5)可以清楚地看到,上半部分和下半部分最大的值正对应车牌字符的上边界和下下边界,据此我们得到准确的车牌定位,见图(7)。按照这个方法,我们能够同时去除车牌字符上方和下方的干扰,并且这个函数对牌照倾斜不敏感。如果在粗定位阶段已经得到了准确的水平定位,那么就不能得到满足大于一定阈值的函数值,不会产生字符被上下切分的情况,具有良好的鲁棒性和适应能力。
3. 实验结果及讨论
为了测试我们的算法的鲁棒性和适应性,我们对从摄像机和数码相机截取的211张图片进行了实验,这些图片有四种不同的分辨率,拍摄于不同地点,不同气候、光照下,有汽车的前脸和后尾的远景、近景和特写照,车型有轿车、小客车、大客车、货车。部分情况的分类见表1:
在粗定位阶段我们全部找到了车牌区域,最后有3张图象中的车牌最后未能准确定位。其中候选区选择错误是由于在客车的车牌斜下方有一个字母和数字组成的标识,是一个类牌照区,由于我们采取识别反馈的方式将识别结果的语法错误反馈回定位阶段,最后我们仍能正确定位此车牌。有一个车牌的水平定位太窄是因为车牌对比度较低并且车牌较大造成边缘图象的不连续行数大于我们在实验中设定的冗余值。另一个车牌的垂直定位太宽是因为车牌的左右两边的尾灯发光时成格子状,具有同车牌字符相似的纹理特征。由于我们在字符分割阶段根据车牌字符的排列特点做了字符区域筛选,根据车牌字符的边缘和灰度做区域增长,最后我们仍能得到正确的分割结果。所以,考虑字符分割和字符识别的反馈我们将进一步提高定位的正确率和准确性。
4. 结论
本文提出了一种新的快速自适应车牌定位算法。在粗定位阶段结合车牌区域的纹理特征和灰度信息定位车牌,接着利用车牌字符的边缘特点精确定位,为下一阶段的车牌字符处理打下了良好的基础。经实验证明,本文提出的方法速度较快,满足整个系统的实时性要求,对车牌大小、长宽比、车牌类型、是否有边框等车牌信息不敏感,对不同的拍摄方式、不同的拍摄条件、不同的图象类型同样具用较好的鲁棒性。由于抓住了车牌共有的特征,本方法有着广泛的适用性,可应用于道路收费、车辆监控、停车场管理等诸多领域




