流式计算之Storm_wordcount例子 storm wordcount 实例
<repository> <id>clojars.org</id> <url>http://clojars.org/repo</url></repository>
<dependency> <groupId>storm</groupId> <artifactId>storm</artifactId> <version>0.5.3</version> <scope>test</scope></dependency>
二.代码范例
1.Topology 入口点 RollingTopWords------------类似于hadoop的Job定义本地模式(嵌入Local):
package storm.starter;import backtype.storm.Config;import backtype.storm.LocalCluster;import backtype.storm.testing.TestWordSpout;import backtype.storm.topology.TopologyBuilder;import backtype.storm.tuple.Fields;import storm.starter.bolt.MergeObjects;import storm.starter.bolt.RankObjects;import storm.starter.bolt.RollingCountObjects;public class RollingTopWords { public static voidmain(String[] args) throws Exception { final int TOP_N = 3; TopologyBuilder builder = newTopologyBuilder(); builder.setSpout(1, new TestWordSpout(),5); builder.setBolt(2, new RollingCountObjects(60,10), 4) .fieldsGrouping(1, new Fields("word")); builder.setBolt(3, new RankObjects(TOP_N),4) .fieldsGrouping(2, new Fields("obj")); builder.setBolt(4, newMergeObjects(TOP_N)) .globalGrouping(3); Config conf = new Config(); conf.setDebug(true); LocalCluster cluster = new LocalCluster(); //本地模式启动集群 cluster.submitTopology("rolling-demo", conf,builder.createTopology()); Thread.sleep(10000); cluster.shutdown(); }}
部署模式:
package storm.starter;import storm.starter.bolt.MergeObjects;import storm.starter.bolt.RankObjects;import storm.starter.bolt.RollingCountObjects;import backtype.storm.Config;import backtype.storm.StormSubmitter;import backtype.storm.testing.TestWordSpout;import backtype.storm.topology.TopologyBuilder;import backtype.storm.tuple.Fields;public class RollingTopWords { public static voidmain(String[] args) throws Exception { final int TOP_N = 3; TopologyBuilder builder = newTopologyBuilder(); builder.setSpout(1, new TestWordSpout(),5); builder.setBolt(2, new RollingCountObjects(60,10), 4).fieldsGrouping( 1, new Fields("word")); builder.setBolt(3, new RankObjects(TOP_N),4).fieldsGrouping(2, new Fields("obj")); builder.setBolt(4, newMergeObjects(TOP_N)).globalGrouping(3); Config conf = new Config(); conf.setDebug(true); conf.setNumWorkers(20); conf.setMaxSpoutPending(5000); StormSubmitter.submitTopology("demo",conf, builder.createTopology()); Thread.sleep(10000); }}
2. 直接使用内置的TestWordSpout(随机产生一个word)TestWordSpout
package backtype.storm.testing;import backtype.storm.topology.OutputFieldsDeclarer;import java.util.Map;import backtype.storm.spout.SpoutOutputCollector;import backtype.storm.task.TopologyContext;import backtype.storm.topology.IRichSpout;import backtype.storm.tuple.Fields;import backtype.storm.tuple.Values;import backtype.storm.utils.Utils;import java.util.Random;import org.apache.log4j.Logger;public class TestWordSpout implements IRichSpout { public static Logger LOG= Logger.getLogger(TestWordSpout.class); boolean_isDistributed; SpoutOutputCollector_collector; public TestWordSpout(){ this(true); } publicTestWordSpout(boolean isDistributed) { _isDistributed = isDistributed; } public booleanisDistributed() { return _isDistributed; } public void open(Mapconf, TopologyContext context, SpoutOutputCollector collector){ _collector = collector; } public void close(){ } public void nextTuple(){ Utils.sleep(100); final String[] words = new String[] {"nathan","mike", "jackson", "golda", "bertels"}; final Random rand = new Random(); final String word =words[rand.nextInt(words.length)]; _collector.emit(new Values(word)); } public void ack(ObjectmsgId) { } public void fail(ObjectmsgId) { } public voiddeclareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); }}
3.各环节处理Bolt
RollingCountObjects 滚动计数word,并通过定时触发时间,清空计数列表
package storm.starter.bolt;import backtype.storm.task.OutputCollector;import backtype.storm.task.TopologyContext;import backtype.storm.topology.IRichBolt;import backtype.storm.topology.OutputFieldsDeclarer;import backtype.storm.tuple.Fields;import backtype.storm.tuple.Tuple;import backtype.storm.tuple.Values;import backtype.storm.utils.Utils;import java.util.HashMap;import java.util.HashSet;import java.util.Map;import java.util.Set;@SuppressWarnings("serial")public class RollingCountObjects implements IRichBolt { privateHashMap<Object, long[]> _objectCounts= new HashMap<Object,long[]>(); private int_numBuckets; private transient Threadcleaner; private OutputCollector_collector; private int_trackMinutes; publicRollingCountObjects(int numBuckets, int trackMinutes) { _numBuckets = numBuckets; _trackMinutes = trackMinutes; } public long totalObjects(Object obj) { long[] curr = _objectCounts.get(obj); long total = 0; for (long l: curr) { total+=l; } return total; } public int currentBucket(int buckets) { return (currentSecond() /secondsPerBucket(buckets)) % buckets; } public intcurrentSecond() { return (int) (System.currentTimeMillis() /1000); } public intsecondsPerBucket(int buckets) { return (_trackMinutes * 60 / buckets); } public longmillisPerBucket(int buckets) { return (long) secondsPerBucket(buckets) *1000; } @SuppressWarnings("rawtypes") public void prepare(MapstormConf, TopologyContext context, OutputCollector collector){ _collector = collector; cleaner = new Thread(new Runnable() { @SuppressWarnings("unchecked") publicvoid run() { Integer lastBucket =currentBucket(_numBuckets); while(true) { intcurrBucket = currentBucket(_numBuckets); if(currBucket!=lastBucket) { int bucketToWipe =(currBucket + 1) % _numBuckets; synchronized(_objectCounts){ Set objs = newHashSet(_objectCounts.keySet()); for (Object obj: objs) { long[] counts =_objectCounts.get(obj); long currBucketVal =counts[bucketToWipe]; counts[bucketToWipe] = 0; //*这行代码很关键* long total =totalObjects(obj); if(currBucketVal!=0) { _collector.emit(new Values(obj, total)); } if(total==0) { _objectCounts.remove(obj); } } } lastBucket =currBucket; } long delta= millisPerBucket(_numBuckets) - (System.currentTimeMillis() %millisPerBucket(_numBuckets)); Utils.sleep(delta); } } }); cleaner.start(); } public voidexecute(Tuple tuple) { Object obj = tuple.getValue(0); int bucket = currentBucket(_numBuckets); synchronized(_objectCounts) { long[]curr = _objectCounts.get(obj); if(curr==null) { curr = newlong[_numBuckets]; _objectCounts.put(obj,curr); } curr[bucket]++; _collector.emit(new Values(obj, totalObjects(obj))); _collector.ack(tuple); } } public void cleanup(){ } public voiddeclareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("obj","count")); }}
RankObjects
package storm.starter.bolt;import backtype.storm.task.TopologyContext;import backtype.storm.topology.BasicOutputCollector;import backtype.storm.topology.IBasicBolt;import backtype.storm.topology.OutputFieldsDeclarer;import backtype.storm.tuple.Fields;import backtype.storm.tuple.Tuple;import backtype.storm.tuple.Values;import java.util.ArrayList;import java.util.Collections;import java.util.Comparator;import java.util.List;import java.util.Map;import org.json.simple.JSONValue;@SuppressWarnings("serial")public class RankObjects implements IBasicBolt { @SuppressWarnings("rawtypes") List<List> _rankings = newArrayList<List>(); int _count; Long _lastTime =null; public RankObjects(intn) { _count = n; } @SuppressWarnings("rawtypes") private int_compare(List one, List two) { long valueOne = (Long) one.get(1); long valueTwo = (Long) two.get(1); long delta = valueTwo - valueOne; if(delta > 0) { return1; } else if (delta < 0) { return-1; } else { return0; } } //end compare private Integer_find(Object tag) { for(int i = 0; i <_rankings.size(); ++i) { Object cur= _rankings.get(i).get(0); if(cur.equals(tag)) { return i; } } return null; } @SuppressWarnings("rawtypes") public void prepare(MapstormConf, TopologyContext context) { } @SuppressWarnings("rawtypes") public voidexecute(Tuple tuple, BasicOutputCollector collector) { Object tag = tuple.getValue(0); Integer existingIndex = _find(tag); if (null != existingIndex) { _rankings.set(existingIndex, tuple.getValues()); } else { _rankings.add(tuple.getValues()); } Collections.sort(_rankings, newComparator<List>() { public intcompare(List o1, List o2) { return _compare(o1,o2); } }); if (_rankings.size() > _count){ _rankings.remove(_count); } long currentTime =System.currentTimeMillis(); if(_lastTime==null || currentTime>= _lastTime + 2000) { collector.emit(newValues(JSONValue.toJSONString(_rankings))); _lastTime= currentTime; } } public void cleanup(){ } public voiddeclareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("list")); }}
MergeObjects 对排序结果进行归并
package storm.starter.bolt;import org.apache.log4j.Logger;import backtype.storm.task.TopologyContext;import backtype.storm.topology.BasicOutputCollector;import backtype.storm.topology.IBasicBolt;import backtype.storm.topology.OutputFieldsDeclarer;import backtype.storm.tuple.Fields;import backtype.storm.tuple.Tuple;import backtype.storm.tuple.Values;import java.util.ArrayList;import java.util.Collections;import java.util.Comparator;import java.util.List;import java.util.Map;import org.json.simple.JSONValue;@SuppressWarnings("serial")public class MergeObjects implements IBasicBolt { public static Logger LOG= Logger.getLogger(MergeObjects.class); @SuppressWarnings({"rawtypes", "unchecked" }) privateList<List> _rankings = newArrayList(); int _count = 10; Long _lastTime; public MergeObjects(intn) { _count = n; } @SuppressWarnings("rawtypes") private int_compare(List one, List two) { long valueOne = (Long) one.get(1); long valueTwo = (Long) two.get(1); long delta = valueTwo - valueOne; if(delta > 0) { return1; } else if (delta < 0) { return-1; } else { return0; } } //end compare private Integer_find(Object tag) { for(int i = 0; i <_rankings.size(); ++i) { Object cur= _rankings.get(i).get(0); if(cur.equals(tag)) { return i; } } return null; } @SuppressWarnings("rawtypes") public void prepare(MapstormConf, TopologyContext context) { } @SuppressWarnings({"unchecked", "rawtypes" }) public voidexecute(Tuple tuple, BasicOutputCollector collector) { List<List> merging= (List) JSONValue.parse(tuple.getString(0)); for(List pair : merging) { IntegerexistingIndex = _find(pair.get(0)); if (null!= existingIndex) { _rankings.set(existingIndex,pair); } else{ _rankings.add(pair); } Collections.sort(_rankings, newComparator<List>() { public int compare(List o1,List o2) { return _compare(o1, o2); } }); if(_rankings.size() > _count) { _rankings.subList(_count,_rankings.size()).clear(); } } long currentTime =System.currentTimeMillis(); if(_lastTime==null || currentTime>= _lastTime + 2000) { StringfullRankings = JSONValue.toJSONString(_rankings); collector.emit(new Values(fullRankings)); LOG.info("Rankings: " + fullRankings); _lastTime= currentTime; } } public void cleanup(){ } public voiddeclareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("list")); }}
更多阅读

金钱草反流性胃炎之克星 胆汁反流胃炎能活多久
说起金钱草很多老百姓都知道是一味治疗胆结石的良药,可以称为妇孺皆知。但是,金钱草能治疗胆汁反流性胃炎的人可能知道的不多,而且方法极简单,特效。对于基层医生和一般稍懂些医学知识的人可以说是一种方便易行的好方法。临床上胆汁反流

静坐冥想的好处和基础步骤及引导式冥想的例子 张德芬静坐冥想30分钟
最近看朵琳·芙秋《灵疗·奇迹·光行者》,收获非常多。这里摘录下来的静坐冥想非常好,实用,方便朋友使用。特分享在此。祝福朋友们在无限的爱与光中!静坐冥想的好处和基础步骤你不需要花上许多冥想才能享有冥想的好处,只要每天早上先

喝粤式早茶必点的点心---虾饺 广式点心之家虾饺
喝粤式早茶必点的点心---虾饺——简介特别喜欢喝粤式早茶,因为它的种类,也许是全国各个地区里最丰富多彩的,不下百种,而且样样精致,让你忍不住想尝尝。但是又恐怕是有心而无力,品种实在是太多啦。这其中有我最钟爱就是这虾饺,每次喝茶必点
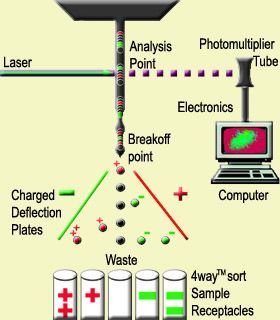
流式细胞胞仪的分析及分选原理 流式细胞结果分析
流式细胞仪由液流系统、光学与信号转换测试系统和数字信号处理及放大的计算机系统三大基本结构组成。在对细胞悬液中的单个细
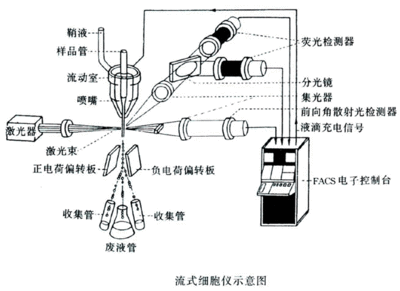
流式细胞仪的功能和临床应用 流式细胞仪的临床应用
流式细胞仪最大的贡献在于促进了免疫学基础研究和临床诊断。目前流式细胞术已被广泛用于细胞生物学、免疫学、肿瘤学、血液学、病理学、遗传学和临床检验等多学科领域的基础和临床研究。1.流式细胞仪的功能(1)细胞参量分析包括细胞大小