ZooKeeper允许分布式的进程之间通过数据寄存器进行相互协作,这些寄存器使用统一的分层级的命名空间来管理(我们称这些寄存器为znode),非常类似于文件系统。和普通的文件系统不同,Zookeeper的客户端拥有高吞吐,低延迟,高可靠,严格按序访问znodes的特性。Zookeeper的多方面性使它被应用于大型分布式系统。在可靠性方面,它避免了在大型系统中的单点失败。它严格顺序的特性允许用户在它的客户端实现复杂的同步原型。
Zookeeper提供的命名空间非常像一个标准文件系统。一个命名是一个序列的路径元素,通过斜杠(“/”)分隔。在Zookeeper的命名空间中,每个znode被定义为一个路径。每个znode有父亲,这个父亲的路径是这个znode的前缀(少了一级目录);这个规则有一个例外,跟目录(“/”)没有父亲。当一个znode存在任何子znode时就不能被删除,这点也和标准文件系统极度类似。
Zookeeper和标准文件系统的主要区别是每个znode可以拥有相关数据(每个文件也可以是一个目录,反之亦然),并限制了所有的znode可以拥有的数据总数。Zookeeper被设计为存储协调数据:静态信息,配置,地址信息,等等。这类元信息通常不是以字节计数,就是以KB计数。Zookeeper有一个固定的合理的上限1M,从而防止它变成巨大的数据存储,但是通常情况下它被用来存储比这小得多的数据。
服务重复的分布在一组机器上组成服务端。这些机器在内存中维持数据树的图像,直到事务以日志和快照的形式保存到持久化存储中。因为数据保持在内存中,所以ZooKeeper能够达到数据的高吞吐和低延迟。内存数据库的缺点是ZooKeeper可以管理的数据库大小受限于存储。这个限制是保持存储在znode的数据量小的深层原因。
这些组成了ZooKeeper服务的服务器必须相互了解。当大多数服务器可用时,ZooKeeper服务将可以使用了。客户端也必须知道服务器列表。客户端使用这个服务器列表对ZooKeeper服务创建一个处理器(handle)。
客户端只连接一台ZooKeeper服务器。客户端通过保持TCP连接发送请求,取得返回,监控事件,发送心跳。如果连接到服务器的TCP连接断开了,客户端将会连接到另一台不同的服务器。当一个客户端第一次连接到ZooKeeper服务器,ZooKeeper服务将会为这个客户端设置一个会话(session)。如果这个客户端需要与另一个服务器连接,这个会话将会在新的服务器上恢复。
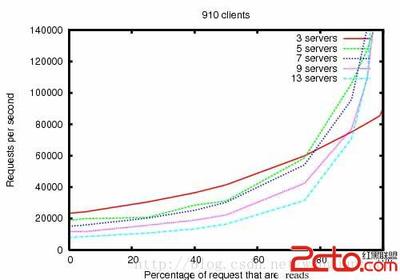
ZooKeeper客户端发送的读请求在该客户端所连接的ZooKeeper服务器的本地处理。如果读请求是注册监视一个znode,这个监视也在ZooKeeper服务器本地被跟踪。写请求被转发到其他ZooKeeper服务器上,达成一致后生成返回(response)。同步请求也被发送到其他服务器上,但不需要达成一致。因此,读请求的处理能力可以通过服务器的数量进行衡量(服务器越多,写能力越强),而写请求的能力随着服务器数量增加而减弱。
顺序对于ZooKeeper来说非常重要;几乎近乎于强迫症。所有更新全部被排序。事实上ZooKeeper用一个数字标记每个更新,从而来体现顺序。我们称这个数字zxid(ZooKeeper Transaction Id)。每个更新拥有唯一的zxid。读(和监视)根据更新的内容被排序。服务这个读请求的读返回将会被标记为最后一个zxid,这个zxid被服务器所处理。